Saving and referencing research software in Software Heritage

Software Heritage allows to archive seamlessly your research software artifacts, and also to add to your research articles precise references to specific versions of the source code, down to fragments of individual source files. This allows to enhance significantly the experience of the reviewers of your work (for example, the artifact evaluation committees), and more generally all of your readers (and one of your readers could even be you in a few weeks, months, or years!).
Fully detailed guidelines are available online, with LaTeX examples, and will be updated regularly: we encourage you to download them and look at them to get the full details.
In this blog post, we summarise the few straightforward steps you need to take: preparing your public repository, saving your code in Software Heritage, and reference it in your work, at different levels of granularity.
Step 1: prepare your public repository
Make sure your source code is hosted on a repository publicly accessible (Github, Bitbucket, a GitLab instance, an institutional software forge, etc.) using one of the version control systems supported by Software Heritage, currently Subversion, Mercurial and Git.
Following well established best practices, include, at the toplevel of your source code tree, the following files:
- README
- contains a description of the software (name, purpose, pointers to website, documentation, development platform, contact and support information, …)
- AUTHORS
- list of all the persons that need to be credited for the software;
if you want to specify the roles of each person, we suggest to use
the taxonomy of contributors elaborated at Inria. - LICENSE
- the project license terms. For Open Source Licenses, use the standard SPDX licence names.
Step 2: save your code
Once your code repository has been properly prepared and up-to date, you need to:
- go to the Software Heritage save code now page,
- pick your version control system in the drop-down list,
- enter the code repository url (the clone/checkout url as given by your development platform),
- click on the Submit button.
That’s it, it’s all done! No need to create an account or to provide personal information of any kind. If the url you provided is correct, Software Heritage will archive your repository, with its full development history, shortly after.
If your repository is hosted on one of the major forges we already know, this process will take just a few hours; if you point to a location we never saw before, it can take longer, as we will need to manually approve it.
Notice that you can also request archival programmatically, using the dedicated Software Heritage API entry point.
Step 3: reference your work
Once your source code has been archived, there are many ways to reference it in your article. Three common use cases are
- adding a link to the full repository archived in Software Heritage
- adding a link to a precise version of the software project
- adding a link to a precise version of a source code file, down to the level of the line of code.
Full repository
The link to the full repository archived in Software Heritage (with all its development history) is obtained by prepending to the URL you used to request its archival the prefix https://archive.softwareheritage.org/browse/origin.
For example, if the repository you have saved is https://github.com/rdicosmo/parmap, then the link to the saved version in Software Heritage will be
https://archive.softwareheritage.org/browse/origin/https://github.com/rdicosmo/parmap/
Following this link, your readers can browse the contents of your repository extensively, delving into its development history, and/or directory structure, down to each single file.
Specific version of the project
Software Heritage provides a fully documented standard identifier schema, called SWH-ID, for pointing to the precise version of all the source code it archives.
For example, the following SWH-ID identifies a precise version of the source code of Parmap:
swh:1:rev:0064fbd0ad69de205ea6ec6999f3d3895e9442c2;origin=https://github.com/rdicosmo/parmap;
SWH-IDs can be turned into a clickable URL by prepending to them the prefix https://archive.softwareheritage.org/. So, the following (hyper)link brings you directly to a page in Software Heritage that is browsing that precise version (try it!)
A very simple way of getting the right SWH-ID is to browse your archived code in Software Heritage, and navigate to the revision you are interested in. Click then on the permalinks vertical red tab that is present on all pages of the archive, and in the tab that opens up you select the revision identifier: an example is shown in figure below:
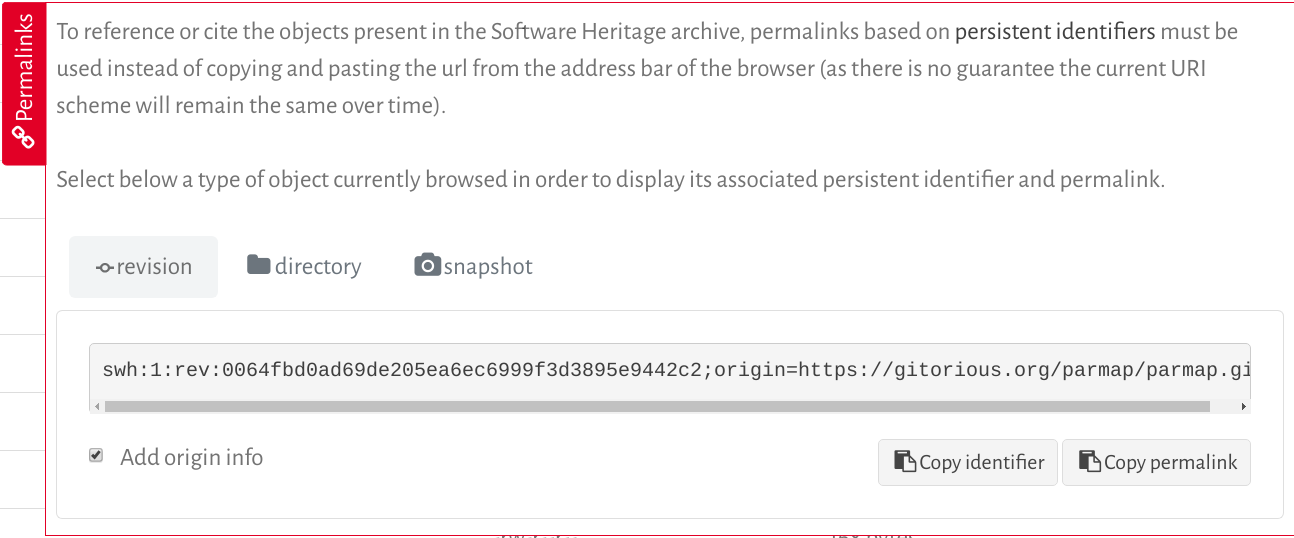
The two convenient buttons on the botton right allow you to copy the identifiers or the full permalink in the clipboard, to insert in your article as you see fit.
Version 1 of the SWH-IDs uses git-compatible hashes, so if you are using git as a version control system, you can create the right SWH-ID by just prepending swh:1:rev: to your commit hash.
Code fragment
SWH-IDs as supported by Software Heritage allow you to go even further and pinpoint a given fragment of code inside a specific version of a file, by using the lines= qualifier available for identifiers that point to files.
For example, the following SWH-ID points to the core mapping algorithm inside the Parmap source code as presented in a research article describing Parmap back in 2012:
swh:1:cnt:d5214ff9562a1fe78db51944506ba48c20de3379;origin=https://github.com/rdicosmo/parmap;lines=101-143
Test it by clicking on this link: you will be brought seamlessly to the Software Heritage archive on a page showing the corresponding source code, with the relevant lines highlighted.
Here too, you can get the exact link by navigating to the code fragment you are interested in the archive, click on the line number of the first line of the fragment, shift-click on the last one, and then open the permalinks tab
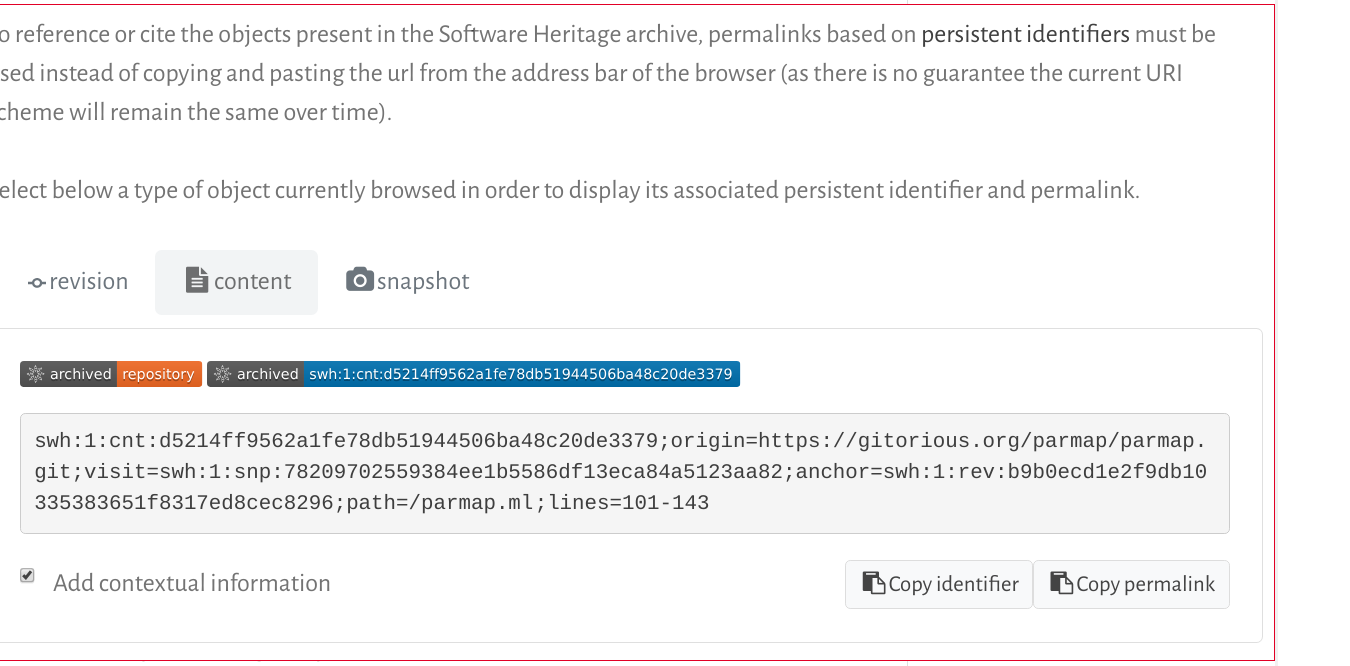
Conclusion
We hope you’ll appreciate the ease with which Software Heritage allows to archive your software source code, hassle-free, as well as the power and flexibility of the SWH-IDs that it offers for enhancing your research articles.
Looking forward to see what you can do with all this!