Traducción realizada por : Jaime Arias, Miguel Colom Barco, José Armando Hernandez Gonzalez, Giacomo Lorenzetti
1. General
1.1 ¿Qué es Software Heritage?
Software Heritage es una infraestructura abierta, sin ánimo de lucro, lanzada en 2016 por Inria. Está apoyada por un amplio panel de instituciones e industriales asociados, en colaboración con la UNESCO.
Expandir para más detalles
El objetivo is colectar todo el software disponible de forma pública en forma de código fuente, junto con su historia de desarrollo, replicarlo masivamente para asegurar su preservación y compartirlo con cualquiera que lo necesite.
Para más información sobre la misión de Software Heritage.
1.2 ¿Qué es el archivo Software Heritage?
El archivo Software Heritage es la colección pública más grande que existe de código fuente. Visite el archivo en https://archive.softwareheritage.org.
1.3 ¿Cuál es el tamaño del archivo?
El archivo crece con el tiempo a medida que recopilamos nuevos códigos fuente de proyectos de software y forjas de desarrollo. Puede ver contadores en tiempo real del contenido del archivo, así como un desglose por orígenes recopilados, en https://archive.softwareheritage.org.
1.4 ¿Cuáles son los servicios de Software Heritage?
Software Heritage es una plataforma mutualizada que ofrece un número creciente de servicios a un amplio espectro de usuarios.
La página features ofrece una visión general de las funcionalidades actualmente disponibles. Esto incluye, por ejemplo, la posibilidad de archivar repositorios de software, navegar los archivos de código fuente y generar identificación persistente.
2. Archivado de software
2.1 ¿Qué plataformas de software (forjas, gestores de paquetes, etc.) se archivan?
Los orígenes de software que actualmente se archivan de forma regular están listados en la página principal del archivo.
Expandir para más detalles
Aquí hay un extracto de esta lista:
- Repositorios git de múltiples forjas (instancias GitHub, Bitbucket, GitLab, cgit, Gitea, Phabricator, etc.)
- Repositorios SVN …
- Repositorios Mercurial …
- Paquetes Debian en apt
- Paquetes Python en PyPi
- Paquetes R en CRAN
- Paquetes NPM en npm.org
- Ficheros zip o archivos tarball en gnu.org
2.2 ¿Si mi código está en GitHub/GitLab/Bitbucket, entonces ya está archivado en Software Heritage?
Podría ser el caso, ya que inspeccionamos estas y otras forjas populares regularmente. Busque su repositorio de código en https://archive.softwareheritage.org/browse/search/.
Expandir para más detalles
Si aún no está, o si la última copia instantánea (snapshot) no es el estado más reciente de su repositorio, usted puede lanzar un nuevo archivo usando la funcionalidad Save Code Now https://archive.softwareheritage.org/save/ o cliqueando en el botón «Save again» en el navegador.
Un GitHub action está disponible para enviar automáticamente una petición Save Code Now. Aquí está un ejemplo de esta acción configurada para que se ejecute cada vez que se publique una nueva versión. También puede usar la extensión del navegador.
2.3 ¿Si elimino el repositorio que contiene mi código, ¿los datos permanecerán en Software Heritage?
Sí, todos los artefactos del código fuente del software se conservan a largo plazo.
2.4 ¿Cuál es la política que determina lo que merece ser archivado? ¿Existen requisitos para que un repositorio de GitHub, GitLab o XXX sea archivado por Software Heritage?
Nosotros no inspeccionamos ni filtramos el código fuente, y archivamos todos lo que podamos encontrar. Por lo tanto, no hay requisitos, pero sugerimos seguir las guías de Software Heritage para mejores resultados.
Expandir para más detalles
La razón de este enfoque es porque el valor del código fuente no puede ser conocido con antelación. Cuando se inicia un proyecto, no se puede predecir si se convertirá o no en un componente clave del software. Por ejemplo, cuando Rasmus Lerdorf lanzó la primera versión de PHP en 1995, quién podría haber predicho que se convertiría en una de las herramientas más populares de la web.

También podría ocurrir que partes muy valiosas de código fuente pasen desapercibidas durante muchos años, hasta que un día un fallo inesperado nos muestra que una parte muy importante de nuestra infraestructura digital depende de ellas.
2.5 ¿Se verifica el código en busca del archivo LICENSE o alguna característica específica en el repositorio antes de archivarlo?
Software Heritage archiva todo lo que está disponible públicamente, sin pruebas ni comprobaciones preliminares.
Esto significa que usted es responsable de comprobar si el código fuente que se encuentra en el archivo se puede reutilizar y bajo qué condiciones.
Para el código que usted produce, le sugerimos que siga las mejores prácticas estándar, que se encuentran en las guías de Software Heritage, incluyendo adicionar información sobre licencias.
2.6 ¿También archivan software ejecutables (archivos binarios)?
Nuestra misión principal es preservar código fuente, ya que es legible por humanos y contiene información preciosa que queda descartada en los ejecutables. En consecuencia no archivamos activamente ficheros binarios, pero, si los binarios están incluidos en un repositorio de software, no los filtramos en el proceso de archivado. Por lo tanto, es posible encontrar algunos binarios en el archivo.
2.7 No consigo encontrar todas mis “releases” en un repositorio git en Software Heritage, ¿qué debería hacer?
No se preocupe, su repositorio ha sido guardado enteramente. Lo que está viendo es solamente una diferencia terminológica entre lo que plataformas como GitHub llaman “releases” (todas las etiquetas git sin anotaciones) y lo que nosotros llamamos “releases” (un nodo del árbol de Merkle, que corresponde a una etiqueta git anotada). Esto es un problema común, debatido por ejemplo en este hilo.
Expandir para más detalles
Por ejemplo, usted etiquetó su release llamándola «FinalSubmission», pero sin usar una etiqueta anotada: en ese caso, no aparecerá en la pestaña “Releases” en Software Heritage, pero, sin embargo, ¡está ahí! Haga clic en el menú desplegable “branch” en la interfaz web de Software Heritage y la encontrará listada como «refs/tags/FinalSubmission». Si usted quiere que su release aparezca en nuestra interfaz web necesita crear sus etiquetas utilizando «git tag -a» en vez de simplemente «git tag», o crear la release directamente en la interfaz de la plataforma de alojamiento, que utiliza el apropiado «git tag -a» detrás de escenas, y luego archiva otra vez el repositorio.
Referencia e Identificación
3.1 ¿Qué es un SWHID (SoftWare Hash Identifier)?
El SWHID (SoftWare Hash Identifier) es un identificador intrínseco persistente que se calcula de forma única a partir del propio artefacto de software. Consulte la publicación del blog dedicada para obtener más información sobre los identificadores intrínsecos y extrínsecos.
Expandir para más detalles
Todos los detalles sobre la sintaxis, la semántica, la interoperabilidad y la implementación se pueden encontrar en la especificación formal.
El siguiente diagrama muestra de forma concisa los componentes clave de un SWHID:
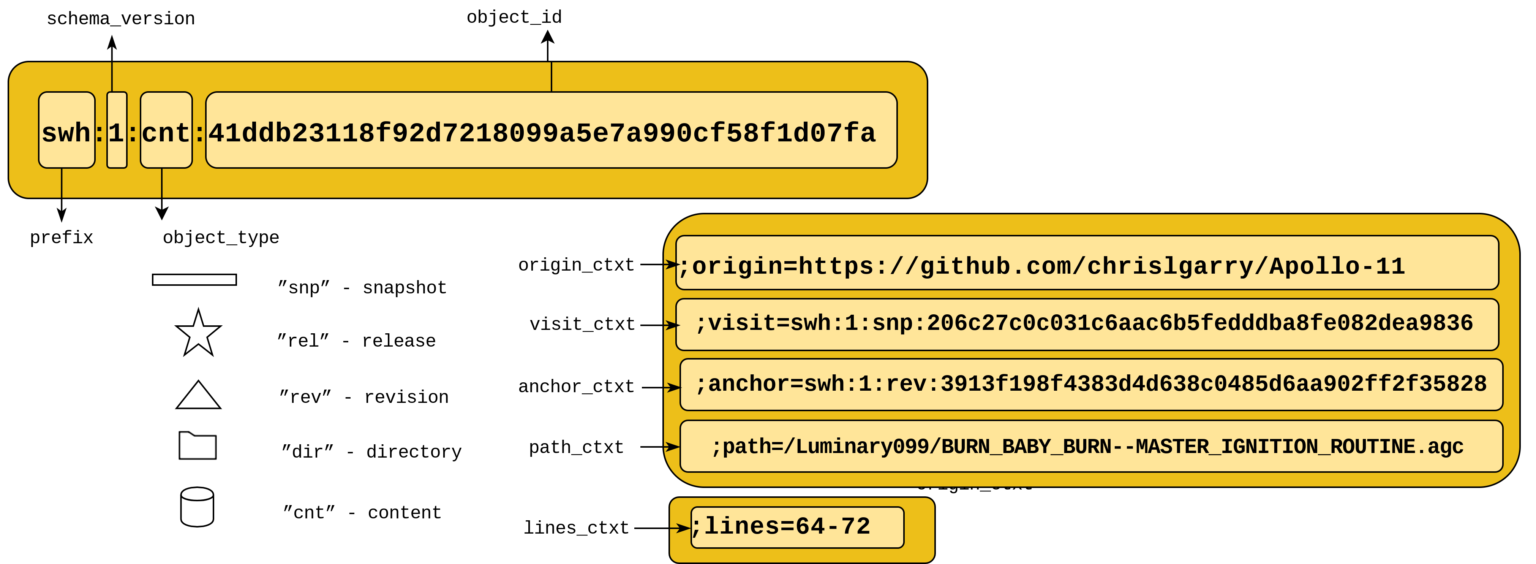
El cuadro amarillo superior del diagrama corresponde a la «parte principal del SWHID» (core SWHID). Es posible añadir qualifiers (calificadores) a un core SWHID para proporcionar información adicional sobre la ubicación del objeto en el grafo de Software Heritage, o su origen, y para identificar fragmentos de código.
3.2 ¿Qué puede ser identificado con un SWHID?
Primero, note que los software pueden ser identificados en diferentes niveles de granularidad, que va del nivel conceptual (e.g. el nombre de un proyecto de software) a artefactos concretos de software (e.g. un directorio con muchos archivos).
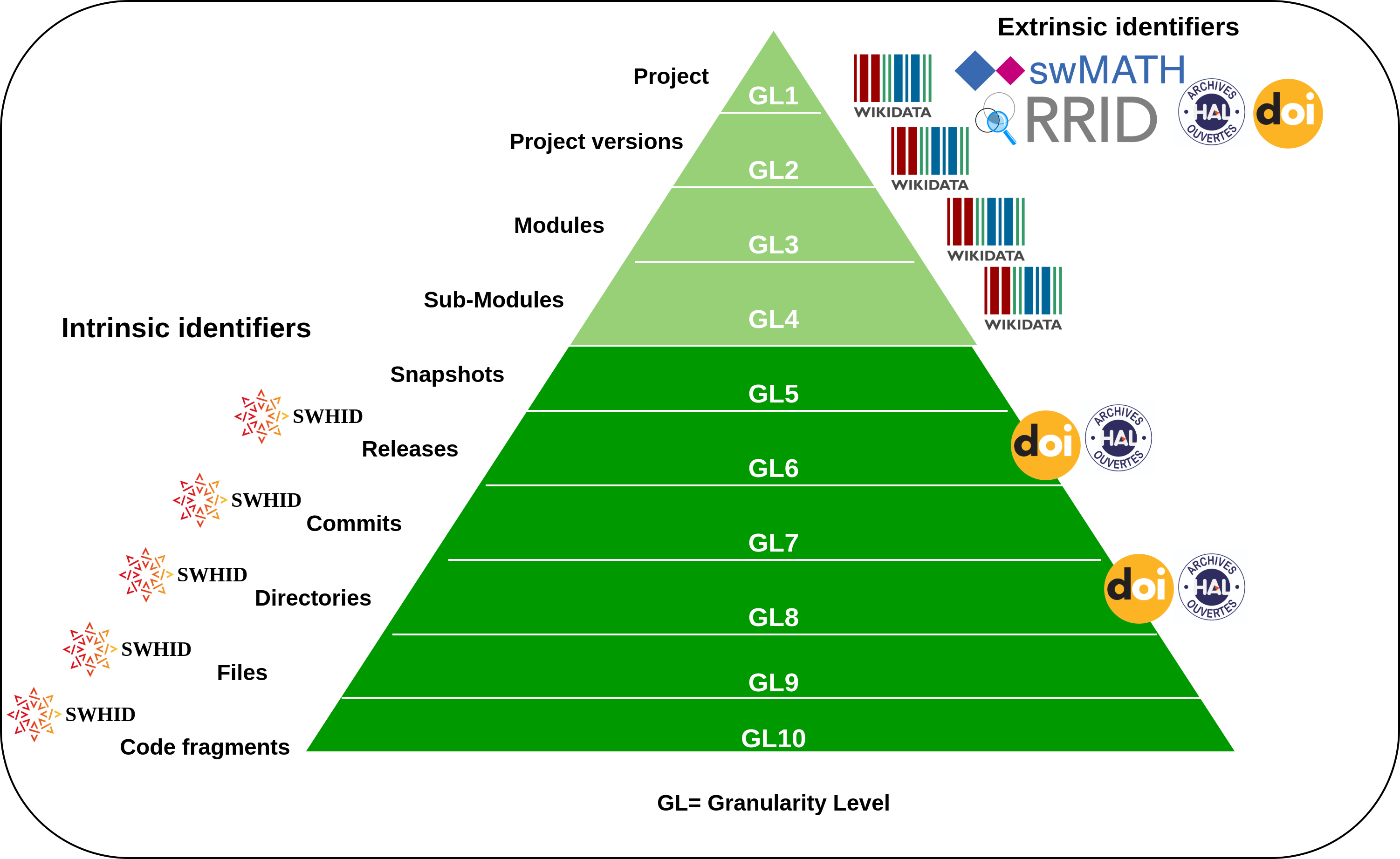
Los SWHID están diseñados para identificar permanentemente e intrínsecamente todos los niveles de granularidad correspondientes a los artefactos concretos de software: snapshots, releases, commits, directorios, archivos y fragmentos de código.
Expandir para más detalles
La parte principal del SWHID puede ser usado para identificar los siguientes artefactos de código fuente:
- Contenido de un archivo; por ejemplo, swh:1:cnt:94a9ed024d3859793618152ea559a168bbcbb5e2 apunta al contenido de un archivo que contiene el texto completo de la licencia GPL3
- directorios; por ejemplo, swh:1:dir:d198bc9d7a6bcf6db04f476d29314f157507d505 apunta a un directorio que contiene el código fuente de la aplicación de fotografía Darktable tal y como estaba en algún momento de mayo 4 de 2017.
- revisiones (commits); por ejemplo, swh:1:rev:309cf2674ee7a0749978cf8265ab91a60aea0f7d apunta a un commit en la historia de desarrollo de Darktable, con fecha de 16 de enero de 2017, el cual agregó la posibilidad de deshacer/rehacer para las máscaras
- releases; por ejemplo, swh:1:rel:22ece559cc7cc2364edc5e5593d63ae8bd229f9f apunta a la versión 2.3.0 de Darktable, de fecha 24 diciembre 2016
- snapshots; por ejemplo, swh:1:snp:c7c108084bc0bf3d81436bf980b46e98bd338453 apunta a una instantánea del repositorio git entero de Darktable tomada el 4 de mayo de 2017 de GitHub
Utilizando el calificador «lines«, también es posible identificar «fragmentos de código«, i.e. líneas de código seleccionadas.
Por ejemplo, swh:1:cnt:94a9ed024d3859793618152ea559a168bbcbb5e2;lines=4-6 señala las líneas 4 a 6 del texto completo de la licencia GPL3.
En términos más generales, el uso de un SWHID completamente cualificado proporciona toda la información relevante para situar un artefacto de software en su contexto. Por ejemplo, el siguiente SWHID señala el algoritmo de mapeo central contenido en el archivo parmap.ml, ubicado en el directorio src de una revisión específica del proyecto Parmap recuperado de https://github.com/rdicosmo/parmap
3.3 ¿Cómo puedo obtener un SWHID para mi software?
La parte principal del SWHID es intrínseco, así que sí, ¡puede calcular la parte principal del SWHID de cualquier artefacto de software localmente en su máquina! ¡Encontrará las instrucciones en la documentación disponible aquí!.
También puede obtener el SWHID completo de cualquier artefacto de software archivado directamente desde el archivo de Software Heritage: usando la pestaña vertical roja llamada «Permalinks», presente en todas las páginas que muestran código fuente (consulte este HOWTO para obtener más detalles). La ventaja de este segundo enfoque es que puede obtener un SWHID con información contextual relevante (e.g. la posición de su artefacto en el grafo global del desarrollo de software).
Expandir para más detalles
La pestaña «Permalinks» le permite obtener un SWHID para el contenido que está navegando. He aquí un ejemplo:
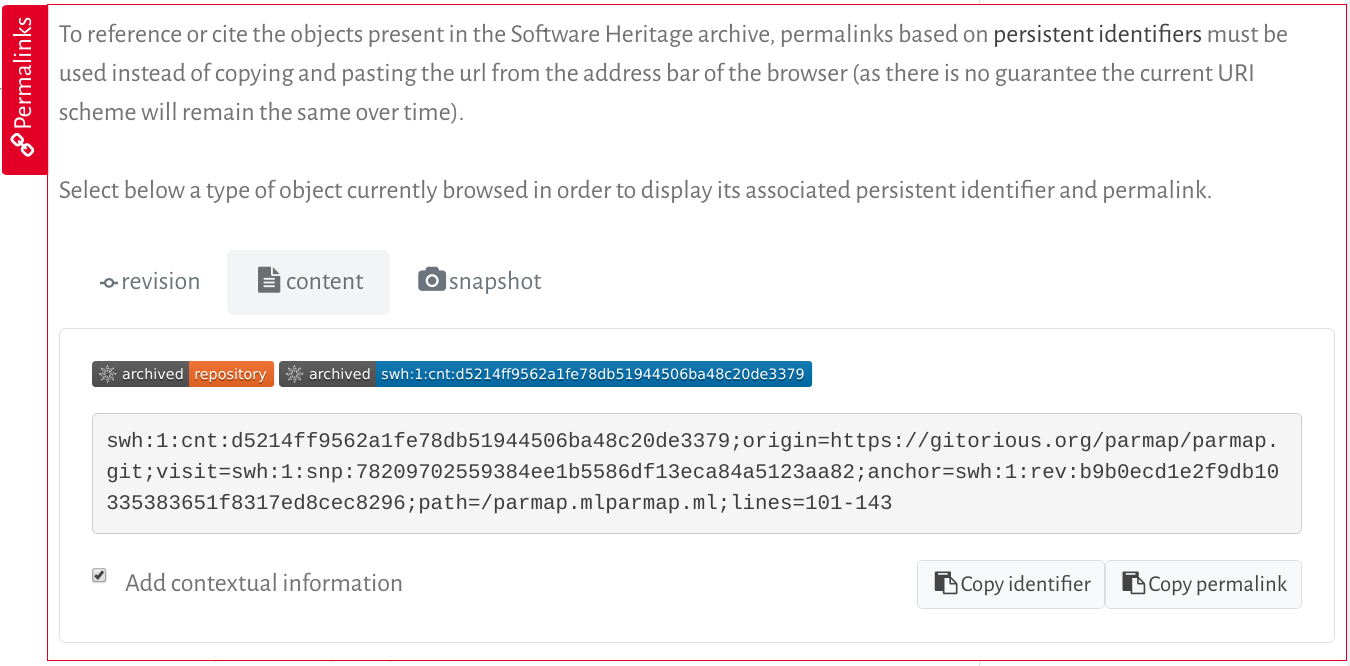
Haciendo clic en «Copy identifier» puede obtener el SWHID en su portapapeles. Haciendo clic en «Copy permalink» puede obtener en su portapapeles la URL correspondiente.
La casilla «Add contextual information» le permite elegir si desea obtener la parte principal del SWHID o el SWHID con los calificadores adicionales que proporcionan información contextual.
Observe que la pestaña Permalinks ofrece una multitud de opciones para elegir un SWHID (puede obtener el del contenido del archivo, el del directorio que lo contiene, el de la revisión, el de la release o el de la snapshot). Vea la siguiente pregunta para comprender cuál es la mejor para su caso de uso.
3.4 ¿Qué tipo de SWHID debería utilizar en mi artículo/documentación?
Realmente depende de su caso de uso, pero una sugerencia general que recomendamos es tomar el SWHID completo de un directorio (con la información contextual).
Expandir para más detalles
Al escribir un artículo de investigación, una entrada de blog o una documentación técnica, uno puedo encontrar cierta tensión entre la necesidad de proveer la máxima cantidad de información, usando un SWHID completo, o mantener una referencia corta (por ejemplo, por una limitación en el número de páginas).
La mejor práctica recomendada para tratar este problema es la siguiente:
- obtener el SWHID completo para el ‘directory’ (directorio) que contiene la versión del código que quiere referenciar. A continuación, un ejemplo de SWHID completo:
swh:1:dir:013573086777370b558b1a9ecb6d0dca9bb8ea18;origin=https://gitlab.com/lemta-rheosol/craft-virtual-dma;visit=swh:1:snp:ef1a939275f05b667e189afbeed5fd59cca51c9d;anchor=swh:1:rev:ad74f6a7f73c7906f9b36ee28dd006231f42552e - asegurarse de que la parte principal del SWHID (
swh:1:dir:013573086777370b558b1a9ecb6d0dca9bb8ea18en el ejemplo anterior) se imprima, y que el SWHID completo esté disponible al menos como un hiperenlace.
Este efecto se puede conseguir como sigue en LaTeX:
\href{https://archive.softwareheritage.org/swh:1:dir:013573086777370b558b1a9ecb6d0dca9bb8ea18;origin=https://gitlab.com/lemta-rheosol/craft-virtual-dma;visit=swh:1:snp:ef1a939275f05b667e189afbeed5fd59cca51c9d;anchor=swh:1:rev:ad74f6a7f73c7906f9b36ee28dd006231f42552e/}{swh:1:dir:013573086777370b558b1a9ecb6d0dca9bb8ea18}
o en Markdown:
[swh:1:dir:013573086777370b558b1a9ecb6d0dca9bb8ea18](https://archive.softwareheritage.org/swh:1:dir:013573086777370b558b1a9ecb6d0dca9bb8ea18;origin=https://gitlab.com/lemta-rheosol/craft-virtual-dma;visit=swh:1:snp:ef1a939275f05b667e189afbeed5fd59cca51c9d;anchor=swh:1:rev:ad74f6a7f73c7906f9b36ee28dd006231f42552e/)
Este enfoque permite que en cualquier versión impresa el lector va a encontrar el identificar que es más útil para reproducibilidad: el SWHID principal del directorio. Ciertamente, el SWHID principal de un directorio se puede calcular localmente desde cualquier instancia de un código fuente, independientemente de la release o del commit que lo contiene en un proyecto específico.
En la versión digital, el enlace clicable usa el SWHID completo para permitir al lector navegar por el código en Software Heritage con el contexto adecuado (versión, origen, etc. etc.).
3.5 Quiero el SWHID completo de un código fuente que aún no está en el archivo. ¿Cómo puedo obtenerlo? ¿Cuánto tardará?
Si su código (o la última versión del mismo) aún no está en el archivo, primero debe iniciar su archivo. Esto puede hacerse con una solicitud «Save Code Now», o a través de la API de depósito.
Una vez enviada una solicitud «Save Code Now», la incorporación del código suele completarse en unos minutos, dependiendo del tamaño del repositorio. Una vez completada, el estado de la solicitud de guardar se actualiza y puede obtener el SWHID como se mostró anteriormente.
Cuando se envía un depósito, la incorporación también suele completarse en unos minutos y se puede acceder al SWHID a través de la respuesta de estado de SWORD.
4. Acceso y reutilización
4.1¿Puedo reutilizar los artefactos de código fuente que encuentro en Software Heritage?
Depende de la licencia del artefacto, tal como se almacena junto con el código fuente: debe verificar esta licencia antes de descargarlo o reutilizarlo. Si no puede encontrar la información de la licencia, debe asumir que no tiene derecho a reutilizarlo.
Expandir para más detalles
Todos los componentes de software presentes en el Archivo pueden estar protegidos por derechos de autor u otros derechos como patentes o marcas comerciales. Software Heritage puede proporcionar información derivada automáticamente sobre las licencias de software que pueden aplicarse a un componente de software determinado, pero no hace ninguna afirmación con exactitud y la información de licencia proporcionada no constituye asesoramiento legal. Usted es el único responsable de determinar la licencia, u otros derechos que se aplican a cualquier componente de software en el Archivo, y debe cumplir sus términos.
4.2 ¿Puedo clonar un repositorio utilizando Software Heritage?
Por favor, no clone un repositorio completo directamente desde Software Heritage: es un archivo, no una forja. Intente primero clonar un repositorio desde el lugar donde se desarrolla: será más rápido y como ventaja añadida ya estará en el lugar adecuado para interactuar con sus desarrolladores.
Expandir para más detalles
Software Heritage almacena todos los artefactos de software en un enorme árbol de Merkle compartido, de modo que exportar (una versión específica de) un repositorio archivado implica recorrer el grafo para obtener todos los contenidos relevantes y empaquetarlos para su consumo. Esta operación es mucho más cara que descargar un archivo tar existente o clonar un repositorio desde una forja.
Si realmente Software Heritage es su último recurso, y no puede encontrar el código fuente de su interés en otra parte, le recomendamos que descargue solamente la versión que le interese, utilizando la opción «directory» del botón Download que encontrará al navegar por el archivo.
Si es absolutamente necesario, puede utilizar la opción más costosa «revision» del botón Download, que preparará para usted el equivalente de un git bare clone, que podrá utilizar sin conexión. Esto puede requerir bastante tiempo (horas, o incluso días para repositorios enormes).
4.3 ¿Puedo recuperar un artefacto de código fuente mediante la API?
Sí, usted puede. Si tiene el SWHID a mano, puede usar el método apropiado de la API para navegar a través de los puntos finales (endpoints) para seguir el grafo de artefactos del proyecto. Consulte la documentación de la API para ver lista de puntos finales completa.
Expandir para más detalles
- /api/1/snapshot/ permite obtener las ramas y etiquetas de la instantánea, cada una con una clave
target_urlque contiene la URL de la - /api/1/release/ o /api/1/revision/ que permite obtener los datos correspondientes a la revisión o la release. Suponiendo que usted obtenga una revisión, la clave
directory_urlcontiene una URL que apunta a: - /api/1/directory/ que lista las entradas del directorio raíz, con los enlaces a otros directorios y objetos de contenido
- /api/1/content/ devuelve toda la información sobre el contenido de un fichero, incluyendo un enlace hacia los datos no procesados.
También puede comprobar un origen y seguir sus visitas:
- /api/1/origin/search/ permite buscar la URL exacta del repositorio del código
- /api/1/origin/visits/ permite listar en cuántas ocasiones Software Heritage visitó el repositorio y obtener una instantánea asociada con cada visita. Para cada visita, la instantánea está disponible como una clave
snapshot_urlque contiene la URL que permite obtener el objeto instantánea correspondiente.
Si está interesado en descargar una parte grande del repositorio (un directorio o un conjunto de revisiones), debería utilizar el servicio de descarga llamado Vault. Vault le permite obtenerlos como por lotes y descargarlos como un archivo tarball. La lista de puntos finales de Vault está disponible al final de la lista de todos los puntos finales de la API
5. Metadatos de software
5.1 ¿Puedo añadir metadatos a mi software?
Un usuario normal puede añadir archivos de metadatos en el repositorio los cuales serán incorporados e indexados cuando se use un formato de archivo específico (codemeta.json, package.json, pom.xml, etc.).
Expandir para más detalles
Siga las guía de Software Heritage sobre cómo preparar su código para el archivo.
Más información sobre los formatos que se indexan y una visión general del flujo de trabajo de metadatos se encuentra en la entrada de blog sobre minería de metadatos de software
5.2¿Qué metadatos se conservan de un repositorio de código, al utilizar la función «save code now»?
Se conservan todos los metadatos que contiene el propio repositorio de código fuente. Esto incluirá el historial de desarrollo y las fechas y mensajes de los commit. Por el momento, otros artefactos de metadatos que no forman parte del repositorio (conocidos como metadatos extrínsecos) no se conservan cuando se usa la función Save Code Now.
5.3 ¿Qué metadatos se conservan con un artefacto de software depositado?
Todos los metadatos que se envían a través del protocolo SWORD que acompañan al artefacto de software. Para más información, visite la documentación del depósito.
5.4 ¿Qué es el archivo codemeta.json, por qué debería utilizarlo?
Como desarrolladores de software, puede que queramos proporcionar una descripción legible por computadores de nuestros proyectos, sin embargo, hay demasiados esquemas de metadatos para describir software y es fácil perderse.
La Iniciativa CodeMeta creó un vocabulario común para tratar este problema, basado en (una pequeña extensión) de las clases SoftwareApplication y SoftwareSourceCode de la bien establecida iniciativa schema.org, y provee herramientas para convertir desde y hacia otros esquemas de metadatos.
El archivo codemeta.json es una representación JSON-LD del vocabulario CodeMeta que se puede generar y validar fácilmente usando la herramienta de código abierto codemeta generator. Al añadir un archivo codemeta.json a su proyecto, facilita compartir la información de metadatos y reduce la carga de tener que volver a escribir mucha información en los formularios de entrada de datos.
Expandir para más detalles
Por ejemplo, el repositorio nacional de acceso abierto francés HAL busca el fichero codemeta.json cuando se deposita un proyecto archivado en Software Heritage y rellena el formulario de depósito a partir de la información que este contiene, ¡un verdadero ahorro de tiempo!
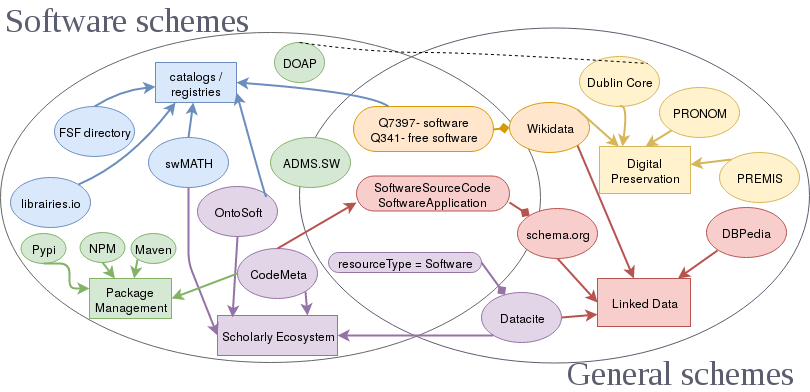
Finalmente, Software Heritage indexa los metadatos contenidos en los archivos codemeta.json y permite realizar búsquedas en la aplicación web mediante la tabla de correspondencias CodeMeta. Esta tabla de correspondencias es la piedra Rosetta de los metadatos de software, facilitando así la traducción entre diferentes ontologías y estándares de metadatos para software.
5.5 ¿Software Heritage comprueba los metadatos (e.g. para verificar si se ha declarado una licencia)?
La respuesta corta es no. Software Heritage no realiza ningún filtrado a priori de los repositorios que se archivan.