It takes a Kraken to scan billions of source files
It’s one thing to collect the world’s open-source code, and another to understand it. The CodeCommons project is working to do just that: map the programming languages and licenses across the entire Software Heritage archive, which contains over 400 million origins. This huge scan will use no less than France’s top supercomputer, CINES’ Adastra, to launch millions of specialized scanners.
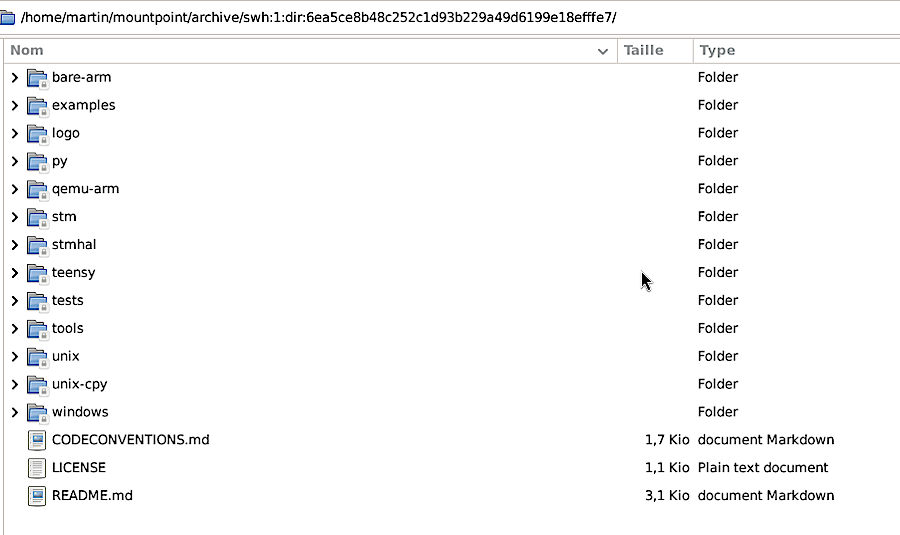
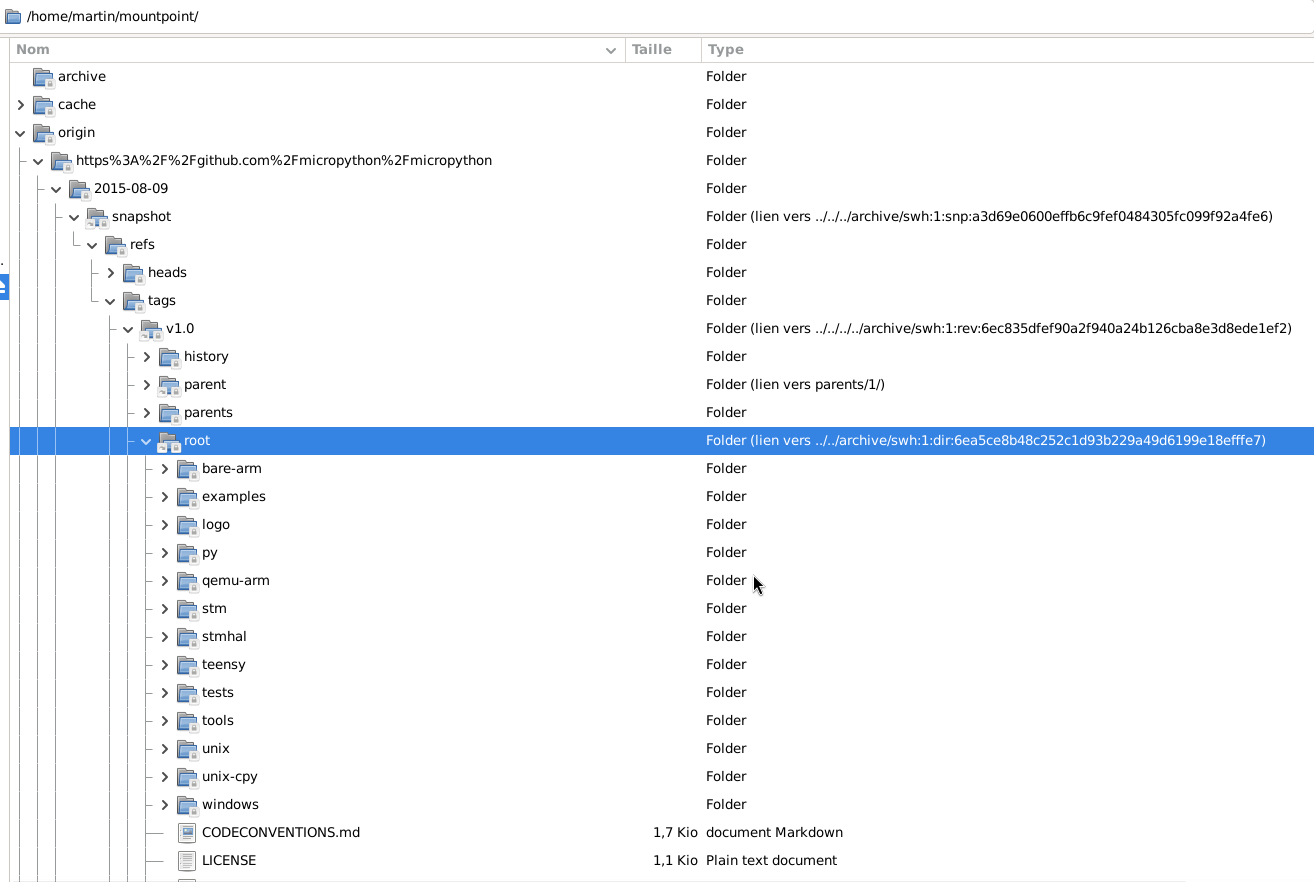
Automated scanners will be able to traverse the archive like a regular folder, thanks to swh-fuse. However, virtual filesystems are not typically known for their speed. To prove it can tackle this massive task, the team recently ran a preliminary experiment on Kraken, the new 10,000-core cluster that just landed in Université Grenoble-Alpes. This experiment, sized at one million origins over 10% of the Software Heritage Archive’s files, is shaping the strategy for the full-scale deployment.
Analyzing hundreds of millions of software repositories isn’t just a technical challenge—it helps us understand the foundations of the digital world, affecting security, innovation, and the history of software development.
CodeCommons is a two-year project building on the foundation of Software Heritage, the world’s largest public source code archive. Funded by the French government with academic partners in France and Italy, its mission is to expand and enhance the archive, consolidating critical, qualified information to create smaller, higher-quality datasets for the next generation of responsible artificial intelligence tools.
The setup: Power and pitfalls
The Kraken cluster is built for raw power, with 10,000 cores over 50 nodes and a vast 300 TB distributed NVMe scratch filesystem. The experiment also aimed at testing the limits of this architecture. The data came from a derivative dataset, TheStackV2, using its most complete variant that contains 2,3 billion files. Two scanners were deployed to perform the analysis: Hyperpolyglot, a programming language detector, and Scancode, a license detector.
Although transferring all those files to storage required a few attempts, the system ultimately validated its performance: writing 8,000 files per second or transferring dozens of gigabytes per second—the level needed for this scale. The biggest hurdle was initiating the enormous volume of small processes and tasks. Standard HPC software is centralized, and attempting to start 10,000 Python processes overloaded the application store. This bottleneck was solved by re-architecting the process spawning mechanism.
The numbers tell a story
When running at full capacity, the cluster processed 1 million origins in under two hours using Hyperpolyglot. That very fast programming language detector turned out to be a load test for our compressed graph server. The system successfully passed the test, and its speed could be further optimized by adding sufficient SSD drives to store the 6TB of highly compressed data.
Scancode, being more CPU-intensive, was run with even greater parallelism, achieving 100 license reports per second. This confirmed the team’s strategy of running more concurrent tasks than available cores to compensate for I/O waits. Under optimal conditions, the file storage was capable of 30,000 reads per second, though this would need to scale significantly for a full-archive scan.
As usual, data locality is a key performance factor. Those experiments confirmed how our compressed exports are relevant to such read-intensive tasks.
What’s next
Above all, the Kraken experiment showed that this bold strategy works: using FUSE filesystems at that scale is unusual, but under the right conditions, it can provide its handy abstraction to many, many scanners. It also reconfirmed that our compressed graph is an incredibly fast tool for traversing the archive.
The experiment also set the bar for the next infrastructure that should be able to serve tens of thousands of files. This calls for preparing compressed maps for archived contents. CodeCommons project members are already working on it, and it might also be useful to publish archive extracts for smaller-scale experiments.
By addressing these challenges, CodeCommons project members are building the foundation to finally understand and map the world’s open-source software.
Learn more
If you’re curious about swh-fuse, get cracking with this tutorial right away.
Ready to see it in action? On November 2, 2025, Martin Kirchgessner will present swh-fuse at PyCon France, showing how this tool enables high-performance computing clusters to access Software Heritage’s archive. More details on the ‘short talks’ page here.