Announcing the Software Heritage Graph Dataset
The mission of Software Heritage is to collect, preserve and share all the publicly available source code, and we have already assembled the largest existing public archive of software source code, spanning tens of millions of software projects. The archive is composed of all the individual source code files, and a huge graph retracing all the history of software development.
We are delighted to announce that the first public dataset encompassing the entire Software Heritage graph is now available. A detailed description, with example of usage, can be found in the following article that has been presented to software engineering researchers at the 16th International Conference on Mining Software Repositories in Montréal – Canada:
- Antoine Pietri, Stefano Zacchiroli and Diomidis Spinellis. The Software Heritage Graph Dataset: Public software development under one roof, MSR 2019: The 16th International Conference on Mining Software Repositories, pp. 138-142
The Software Heritage graph dataset
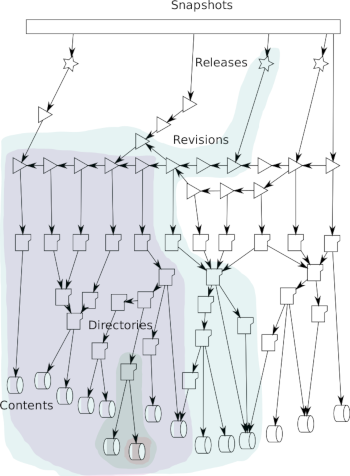
The Software Heritage graph dataset is a representation of the fully-deduplicated Merkle DAG of the Software Heritage archive.
It links together file content identifiers, source code directories, commits in version control systems (VCS) tracking evolution over time, up to the full states of VCS repositories as observed by Software Heritage during periodic crawls.
«Think of it as a single git repository with all the public code in the world».
The dataset’s contents come from major development forges such as GitHub and GitLab, FOSS distributions – like Debian – and language-specific package managers as PyPI.
Crawling information is also included, providing timestamps about when and where all archived source code artifacts have been observed in the wild.
How to get the dataset
The Software Heritage graph dataset is available in multiple formats, including downloadable CSV dumps and Apache Parquet files for local use (downloadable from Zenodo), as well as a public dataset on AWS that can be explored using the Amazon Athena interactive query service.
Source code file contents are cross-referenced at the graph leaves, and can be retrieved through individual requests using the Software Heritage archive API (which can be accessible via a Web UI as well as a Web API).
The floor is yours!
Now you can start analysing the largest software evolution graph in the world: we are really looking forward to see what you can make of it!
And if you would like to work with us on the Software Heritage dataset, contact us!