Software Heritage Citation Feature: Addressing researcher needs

Following GitHub’s lead, Software Heritage now has built-in citation support. This is a big step towards finally recognizing software as a real research output.
This blog post gives a quick rundown of the important news and how Software Heritage is shaking things up for citing software. We’re tackling a problem that’s been around for ages and offering a fix.
Citation made easy with Software Heritage
.bib files.Citing a specific software version—or even a precise code fragment—is just as simple: select the version or highlight the lines of code, and you’re ready to go.
Before diving deeper into the challenge of credit, it’s helpful to understand what’s already achievable using Software Heritage’s existing tools for software reference and preservation.
The universal archive of Software Heritage allows researchers and developers to:
-
Prepare their repositories with key metadata files (
AUTHORS,README,LICENSE,codemeta.json, etc.) -
Trigger archival using the Save Code Now interface, the browser extension, or a webhook
-
Obtain a Software Hash Identifier (SWHID)—a persistent, verifiable reference to a specific version or component. With the new citation feature, you can generate a ready-to-use BibTeX citation directly from the archived object, offering a more robust and reliable alternative to citing a forge URL.
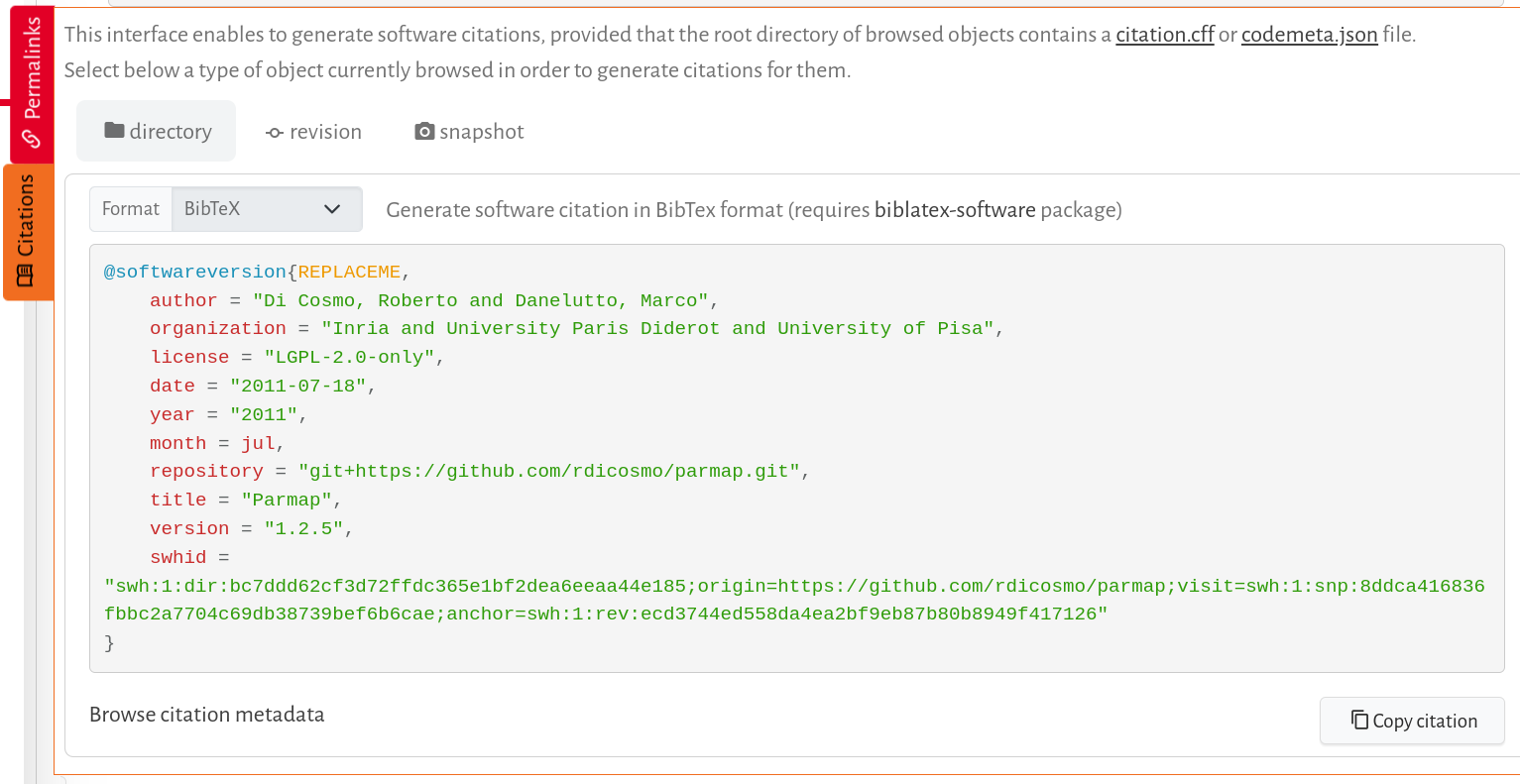
Software Heritage can automatically generate a BibTeX citation using the intrinsic metadata archived from a software repository. This metadata is typically sourced from either a codemeta.json or a citation.cff file found in the repository.
To make citing code easier, users can embed a specific version or fragment of code directly into webpages using iframes. A simple Web UI endpoint is provided for this purpose. Here’s an example:
A long, intertwined journey
- Credit
- Understanding research fields
- Discovering software
- Reproducibility
These goals are crucial, but not exactly straightforward. To make them happen, we need to look at the practical parts of «software citation.» We’re drawing on the guidance from the European Open Science Cloud (EOSC) report on Scholarly Infrastructures for Research Software (December 2020), full report here. The 94-page report outlines practical recommendations to improve the current landscape by building on and connecting existing infrastructures.
Breaking down software citation components
-
Archival: Ensuring long-term preservation and accessibility to the source code
-
Reference: Accurately identifying the exact version used, to ensure reproducibility
-
Description: Capturing structured, well-curated metadata about the software
-
Credit: Acknowledging all contributors involved in the software project
Among these, the most complex and often debated issue is credit— how credit can be given? What «thing» do we want to cite?
Artifacts granularity – SWHIDs in citations
Software is often difficult to cite precisely due to its layered and modular structure. Even small projects usually have several parts, so citing a specific version—or even a specific commit—might be needed for reproducibility or clarity.
While DOIs are widely used to cite publications and datasets, software presents different challenges. As Software Heritage co-founder Roberto Di Cosmo and co-authors note:
“[…] we need identifiers that are not only unique and persistent but also intrinsically support integrity.” (Di Cosmo et al., 2018)
This means relying not on a centralized registry, but on cryptographic techniques. SWHIDs meet this need by being computed directly from the content of the digital object, using cryptographically secure hashing algorithms. Anyone with a copy of the object can independently verify the identifier, making SWHIDs uniquely resilient and trustworthy.
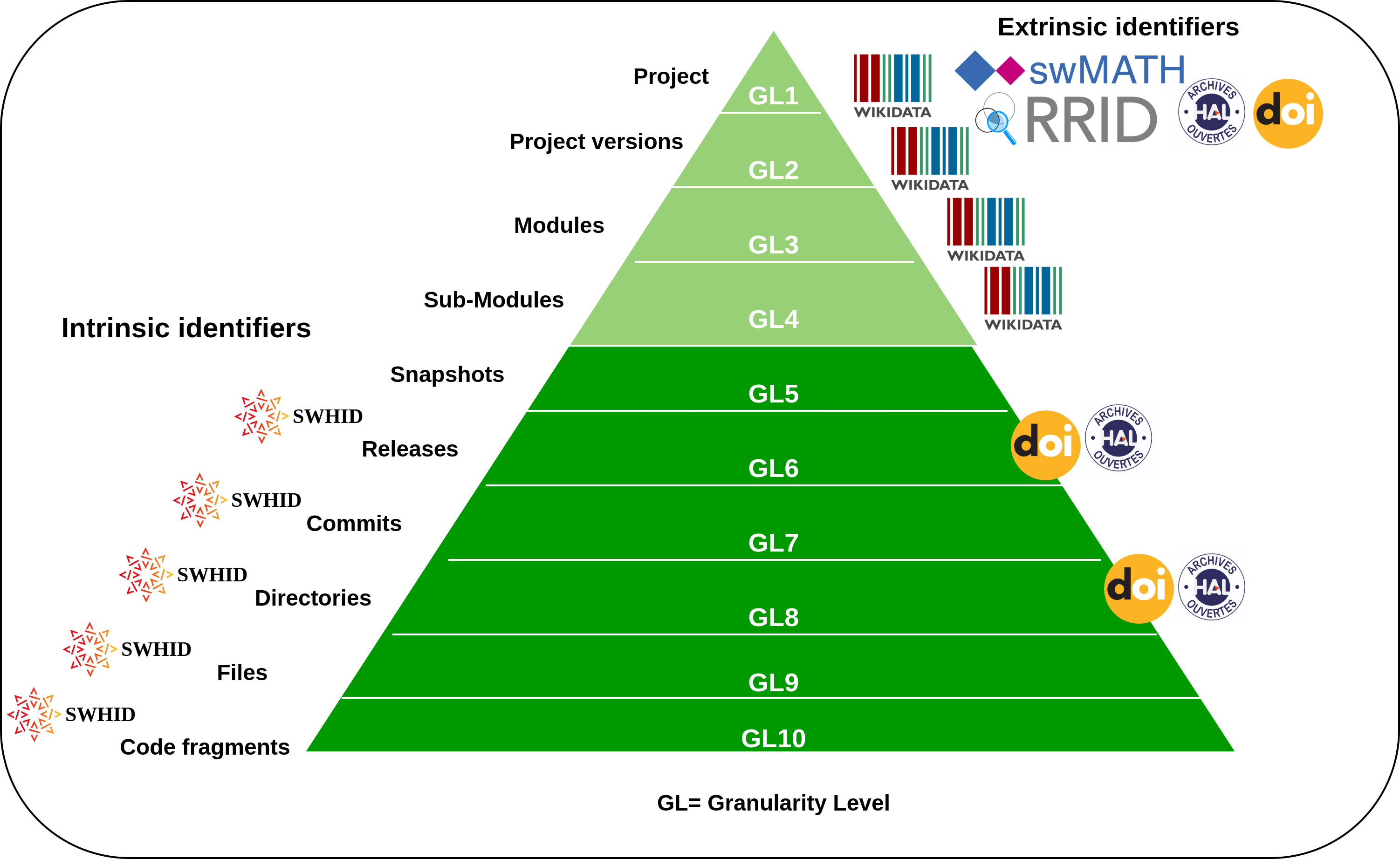
Research Data Alliance/FORCE11 Software Source Code Identification WG, 2020, https://doi.org/10.15497/RDA00053
Why is software attribution so hard?
Sometimes, the list of individuals involved in a software project is very long, so long that it’s not feasible to include everyone directly in a citation. As a result, a common practice has emerged: attributing authorship to the project team or collective entity. For instance, the software record might list “The Givaro group” as the author.
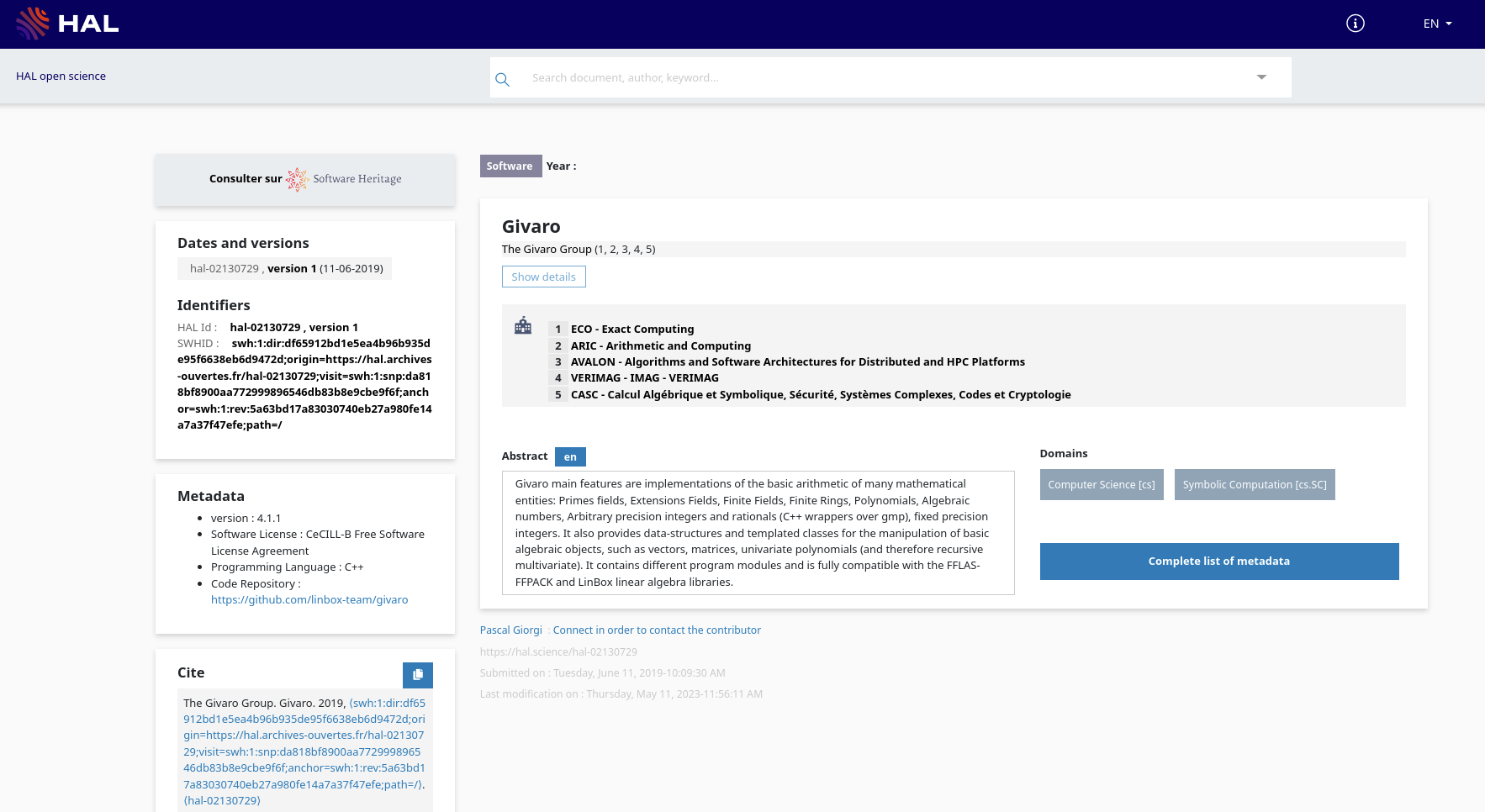
How should credit be given?
Just like with articles where the writers are the authors, we usually assume the developers of code are software authors. However, like everything else about software, it’s more complicated than it looks. Software projects involve many different roles, so the simple term «author,» even with «contributor» added, definitely doesn’t cover everyone involved. One paper, «Attributing and Referencing (Research) Software: Best Practices and Outlook From Inria,» identifies nine key roles, similar to what the CRediT system does for research articles, based on extensive real-world experience. Other communities have also identified the need for distinguishing different software roles. (See the SORTÆD example for a Software Role Taxonomy and Authorship Definition.)
But is this approach sufficient?
The answer largely depends on the infrastructure behind the citation, specifically, whether it can maintain the relationships between the software and the people who contributed to it. A named group is only meaningful if it can be linked to individual members, their roles, and the context of their contributions.
Here, Software Heritage offers a solid base. While citations may remain concise, the underlying metadata, especially when enriched with structured information like codemeta.json or citation.cffcan hold detailed attribution records. These can include individual contributors, their specific roles, and even ORCID identifiers to ensure long-term traceability.
This layered approach balances concise citation with rich, machine-readable credit, helping infrastructure bridge the gap between recognition and practical constraints.
Ultimately, giving credit in software requires more than just a name on a list—it requires context, clarity, and systems that respect the complexity of collaborative work. And that’s exactly what we aim to support through Software Heritage’s evolving citation tools and metadata practices.
Finally, the @software type in BibTeX gets long-awaited improvements
The @software entry type in BibTeX has been around for a long time, but it was just a placeholder, treated like the @misc entry. In 2020 it was finally enriched with long-awaited metadata for software — a major milestone for software citation in academic publishing.
Thanks to the biblatex-software package available on CTAN, you can now cite software with much greater precision using four dedicated entry types that reflect different levels of granularity:
-
@software— for general references to computer software -
@softwaremodule— for citing a specific module within a larger software project -
@softwareversion— for referencing a particular version of a software -
@codefragment— for pinpointing a specific code fragment, such as an algorithm or a key function within a program or library
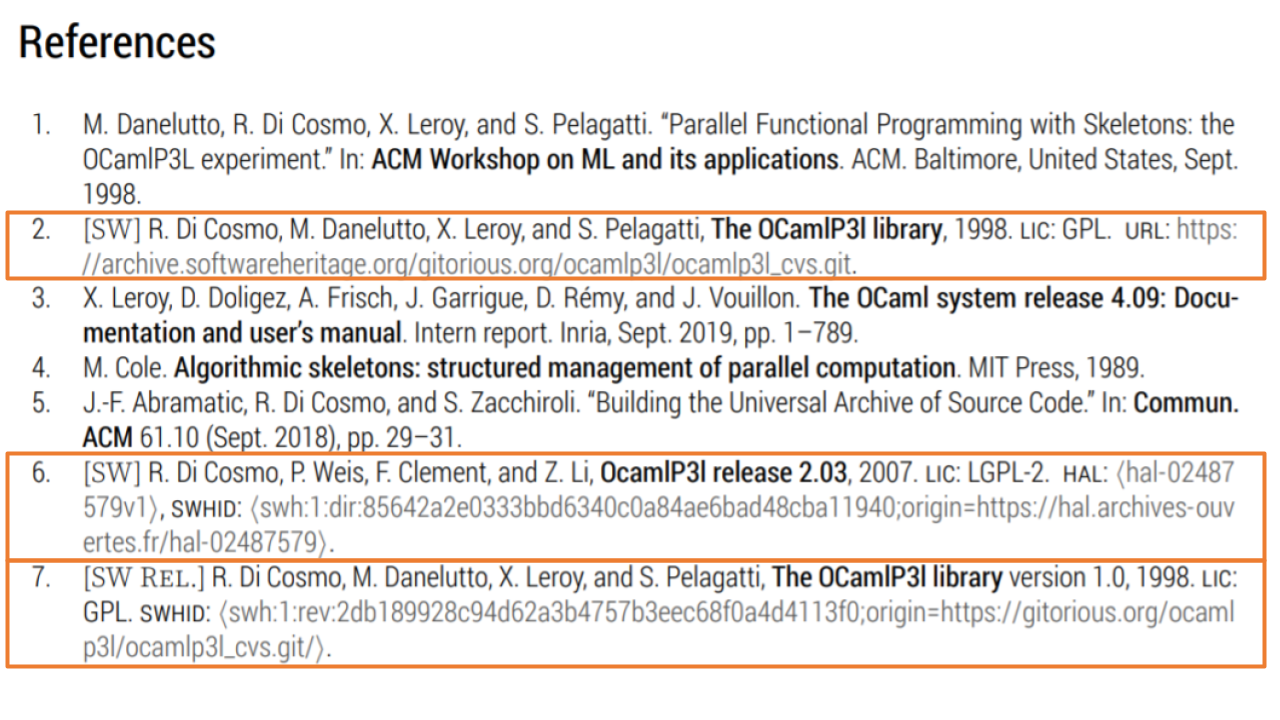
Here’s an example of how this can be implemented using the biblatex-software package. The sample below (entries 2, 6, and 7) demonstrates how tags distinguish between software projects and specific releases:
[Rp] Reproducing and replicating the OCamlP3l experimentReScience C, 6 (1), 2020 https://doi.org/10.5281/zenodo.4041602
The road ahead… and a word of caution
In short, we’ve achieved real progress on several fundamental parts of software citation. Now, you can archive, properly reference, and even directly cite any piece of source code from the universal archive. A standard for describing software is taking shape, and there’s growing experience and expertise in curating this metadata and navigating the nuanced challenge of assigning appropriate credit.
We hope these emerging best practices will be adopted by stakeholders beyond Europe, where the EOSC SIRS report and the FAIRCORE4EOSC project have laid crucial groundwork, but also globally.
Nevertheless, it’s important to acknowledge that the question of «how credit is assigned» remains a highly sensitive and intricate challenge, an issue well documented by the DORA declaration and echoed in earlier reflections from the computer science community.
We must avoid repeating these errors with software. The risks could actually be even greater. Simply relying on citation counts for credit could unintentionally harm how we see the value of different software contributions.
As the EOSC SIRS report wisely cautions:
Metrics should not be reduced to simple numeric indicators, to avoid reproducing in the research software world the negative effect that bibliographic indicators have had in the research publishing world. It is necessary to bring together a broad spectrum of expertise, and include in the conversation representatives of the research community that will be directly impacted by the creation of these metrics.