No science without source: Collecting, preserving and sharing software in a risky world

The biggest act of digital altruism in human history is also one of its most endangered commons. That’s the uncomfortable truth at the heart of what Software Heritage has been doing — and fighting — since 2015.
Director Roberto Di Cosmo laid it out plainly at the ERCIM Forum Beyond Compliance: open source software is everywhere, it underpins virtually all of modern science and industry, and most people have no idea how close we are to losing enormous chunks of it on a regular basis. Catch the whole 26-minute talk on YouTube and check out the presentation slides.
Software is not data. It’s more than that.
Di Cosmo opened the session on data altruism by crossing out the word «data,» instantly shifting the focus for an audience gathered to discuss research ethics in the digital age. Software is not data. It’s the living record of how humans have solved problems computationally across more than 70 years of computing history. It’s in every discipline. It’s in sociology, in law, in molecular biology, in the R scripts that statisticians write and never publish, but that underpin their entire analysis. France’s National Open Science Monitor — which runs machine learning models across all publications with at least one French researcher — found software mentioned across every single scientific field. Every last one.
And it doubles in volume roughly every two years. That rate has held constant since the early 2000s, with no sign of slowing.

The fragility nobody talks about
In 2015, Google Code and Gitorious shut down at short notice. Nearly a million repositories were simply unplugged. Then in 2020, Bitbucket removed Mercurial support. In 2022, GitLab floated the idea of dropping projects with no activity in over a year. Even Inria — which really ought to know better — shut down its own legacy forge, announced the migration, and promptly broke the entire build system for the OCaml programming language when the server went dark ahead of schedule.
«Things are very, very, very fragile,» Di Cosmo said, with the particular emphasis of someone who has lived through all of it.
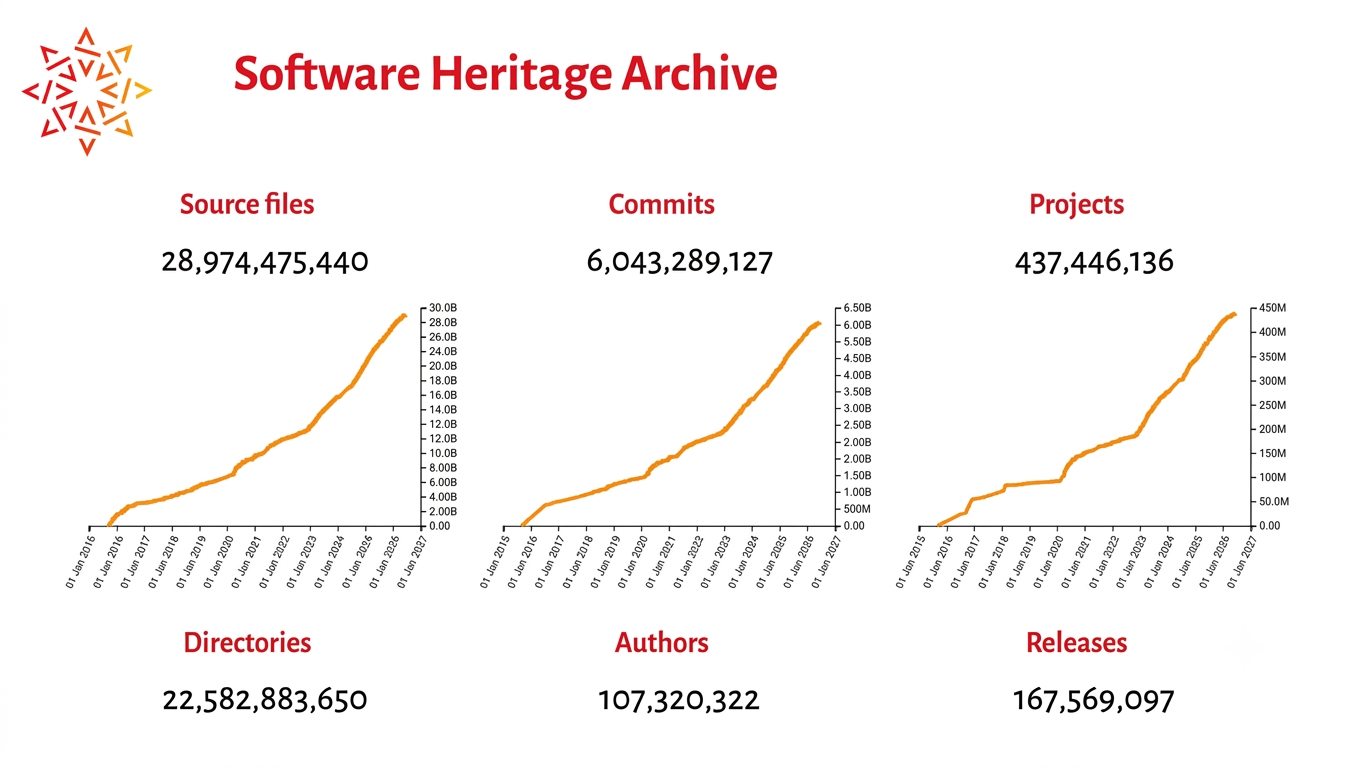
This is what Software Heritage was built to address: a single, open, nonprofit Archive that collects from more than 5,000 platforms — GitHub, GitLab, Bitbucket, Debian, PyPI, npm, and hundreds more — and rebuilds the entire history of software development into one unified data structure. A graph with 50 billion nodes, 1 trillion edges, and two petabytes of storage and counting. Probably the largest social graph on the planet that is publicly available, and almost certainly the only one built for the benefit of all of humankind rather than for an advertising business.
More than 400 million projects. More than 28 billion unique files. And it rescued what was lost: Gitorious, Google Code, and the Bitbucket repositories that were deleted are inside the archive.
Three threats you didn’t see coming
The technical challenge of running a planetary-scale archive is the easy part. The harder part is a set of threats that nobody anticipated when the project launched — and that reveal just how fragile the legal and regulatory environment around shared digital infrastructure really is.
The copyright reform that almost killed open source. The European Directive on Copyright was designed to make hyperscalers pay news publishers. What it nearly did was make open-source software development illegal in Europe as a side effect. It took a year and a half of lobbying to carve out an exception for software. A year and a half.
GDPR’s unintended consequences. The General Data Protection Regulation (GDPRpattern of behavior: developers who contributed to open-source projects began demanding that archives remove their contributions or their names, on the grounds that, since their names) is a fundamentally good idea. But it created an unexpected behavior pattern: developers who contributed to open source projects started demanding that archives remove their contributions, or remove their names, on the grounds that since their name appeared in the commit history, they had the right to control whether the software could be stored. This is not what GDPR was designed for. But it is happening, constantly, at scale.
The Cyber Resilience Act and the end of frictionless sharing. The CRA is coming, and it attaches liability to software distribution. The logic is sound from a security perspective. The unintended consequence is that people who have been freely sharing software may simply stop: if sharing means being responsible for the security of what you share, some will conclude it is easier to delete.
The AI reckoning
In 2023, Software Heritage got hit by what Di Cosmo calls the tidal wave. Companies came asking for the full archive to train AI models. It was, if you think about it, a remarkable thing: after about a decade of open, transparent, mission-driven work to build the collective computational knowledge of humanity — and the first major external demand for it was from companies building billion-dollar products.
Software Heritage said yes, conditionally. There are three conditions: any company using the archive to train models must make the foundational model — the base model, not the fine-tuned production version — publicly available back to humanity. Full transparency on what was used for training, tracked via cryptographic identifiers. And an opt-out mechanism for authors who do not want their code used.
HuggingFace and Nvidia signed. The result was StarCoder 2 — which was, at the time of release, the best open model for programming. IBM and Infosys have since signed the same agreement. Slowly, with three simple principles, a different norm is being established for AI and software.
The license problem nobody wants to look at
Here’s a number that should stop you: across all the software publicly available to which French academic institutions contribute, more than three-quarters of projects have no license whatsoever.
Not a permissive license. Not a restrictive license. No license. Which means, legally, that software cannot be freely used, modified, or redistributed by anyone — including the researchers who want to build on it for open science. The authors almost certainly did not intend this. They just didn’t know they needed to add a license. But the result is a vast commons that is legally unusable.
And while that is being sorted out — slowly, through working groups and policy conversations — more than three-quarters of the software produced by European academic institutions is hosted on development platforms that are not under European control. GitHub and GitLab. American infrastructure. Which is fine, right up until it isn’t.
Why this matters for science specifically
Reproducibility in research depends on being able to find and run the software associated with a paper. When that software lives on a platform that gets shut down, or on a repo that gets deleted, or under a commit history that a developer has demanded be removed from the archive, the scientific record breaks. It has already broken, repeatedly, for papers that pointed to code that is now gone. Software rot is real.
Software Heritage’s answer is an intrinsic identifier, a cryptographic hash that makes every artifact in the archive citable, verifiable, and permanently referenceable, called the SWHID, now an ISO standard. Cite the code you used. Link it to the Archive. The reproducibility problem, at least for software, becomes solvable.
The harder problem — detecting licenses at scale, attributing authorship across 2,000 forks of the same codebase, giving researchers and AI companies a clean, qualified, legally usable dataset — is what the CodeCommons project exists to address. The goal is a single point where someone can say: Give me all projects under a GPL license, written in Rust or Python, used in molecular biology, actively maintained, with no known vulnerabilities. And get it.
That’s not here yet. But the archive that makes it possible already exists.