1. General
1.1 What is Software Heritage?
Software Heritage is an open, non-profit infrastructure launched in 2016 by Inria. It is supported by a broad panel of institutional and industry partners, in collaboration with UNESCO.
Expand for details
The long-term goal is to collect all publicly available software in source code form together its development history, replicate it massively to ensure its preservation, and share it with everyone who needs it.
For more information about the Software Heritage mission.
1.2 What is the Software Heritage Archive?
The Software Heritage archive is the largest public collection of source code in existence. Visit the archive at https://archive.softwareheritage.org.
1.3 How big is the Archive?
You can see live counters of the archive contents, as well as a breakdown by crawled origins, on https://archive.softwareheritage.org.
1.4 What services does Software Heritage provide?
Software Heritage is a shared platform that provides a variety of services to a wide range of users.
The features page provides an overview of the features currently available. This includes, for example, archiving software repositories, browsing the archived source code, and providing persistent identification.
2. Archiving software
2.1 Which software platforms (forges, package managers, etc.) are archived?
The software origins that are currently regularly archived are listed on the main archive page.
Expand for details
Here is an excerpt of this list:
- Git repositories from multiple forges (GitHub, Bitbucket, GitLab instances, cgit instances, Gitea instances, Phabricator instances, etc.)
- SVN repositories…
- Mercurial repositories…
- Debian packages in apt
- Python packages in PyPI
- R packages in CRAN
- NPM packages in npm.org
- zip or archives tarballs in gnu.org
2.2 If my code is on GitHub/GitLab/Bitbucket, is it already archived in Software Heritage?
It might be, as we crawl these and other popular forges regularly.
Search for your code repository on https://archive.softwareheritage.org/browse/search/.
Expand for details
If it is not there yet, or if the latest snapshot is not the most recent state of your repository, you can trigger a new archival using the Save Code Now functionality
https://archive.softwareheritage.org/save/ or by clicking on the « Save again » button in the browse view.

A GitHub action is available to automatically push a save code now request. Here is an example of this action configured to run each time a new release is issued.
You can also use the browser extension.
2.3 If I delete the repository that contains my code, will the data stay in Software Heritage?
Yes, all software source code artifacts are preserved for the long term.
2.4 What is the policy for determining what deserves to be archived? Are there requirements for a GitHub, GitLab or XXX repository to be archived by Software Heritage?
We do not inspect or filter the source code, and archive anything that we can get hold of. As a consequence, here are no requirements but we do suggest following the Software Heritage guidelines for best results.
Expand for details
The reason for this approach is because the value of software source code cannot be known in advance. When a project starts, one cannot predict whether it will become a key software component or not. For example, when Rasmus Lerdorf released the first version on PHP back in 1995, who could have predicted that it would become one of the most popular tools for the Web.

And it also happens that very precious pieces of source code may be go unnoticed for decades, until one day some unexpected bug unveils that a big part of our digital infrastructure relies on them.
2.5 Is the code checked for LICENSE file or any specific characteristic in the repository before archiving?
Software Heritage archives everything that is publicly available, without preliminary tests or checks.
This means that you are responsible for checking whether the source code you find in the archive can be reused, and under which terms.
For the code that you produce, we do suggest following standard best practices, that are recalled in the Software Heritage guidelines, and this include adding licensing information.
2.6 Do you also archive software executables (aka binaries)?
Our mission is to preserve source code, as it contains human-readable information not found in executables. Because of this, we don’t actively collect binaries. However, if binaries are included in a software repository, we do not filter them out during the archival process. This is why you will find some binaries in the archive.
2.7 I can’t find all my « releases » in a git repository in Software Heritage, what should I do?
Do not worry, your repository has been saved in full.
What you are witnessing is just a terminological difference between what
platforms like GitHub calls « releases » (any non annotated git tag) and what we call « releases » (a node in the Merkle tree, which corresponds to a git annotated tag). This is a common issue, as you can see for example in this discussion thread.
Expand for details
Let’s say you tagged your release naming it « FinalSubmission », but you did not use an annotated tag: in this case, it will not show up in the Releases tab on Software Heritage, but it is there nonetheless! Click on the branch dropdown menu on the Software Heritage Web interface and you’ll find it listed as « refs/tags/FinalSubmission ». If you want a release to appear in our web interface you should create your tags
using « git tag -a », instead of simply « git tag », or create the release directly on the code hosting platform, that uses the proper « git tag -a » behind the scenes, and then archive your
repository again.
3. Referencing and identification
3.1 What’s the SoftWare Hash Identifier (SWHID)?
The SWHID (SoftWare Hash Identifier) is a unique and permanent identifier for a piece of software, derived directly from the code’s content. It became ISO/IEC international standard 18670 on April 23, 2025.
Expand for details
Details about the syntax, semantics, interoperability, and implementation can be found in the formal specification.
The following diagram shows concisely the key components of an SWHID:
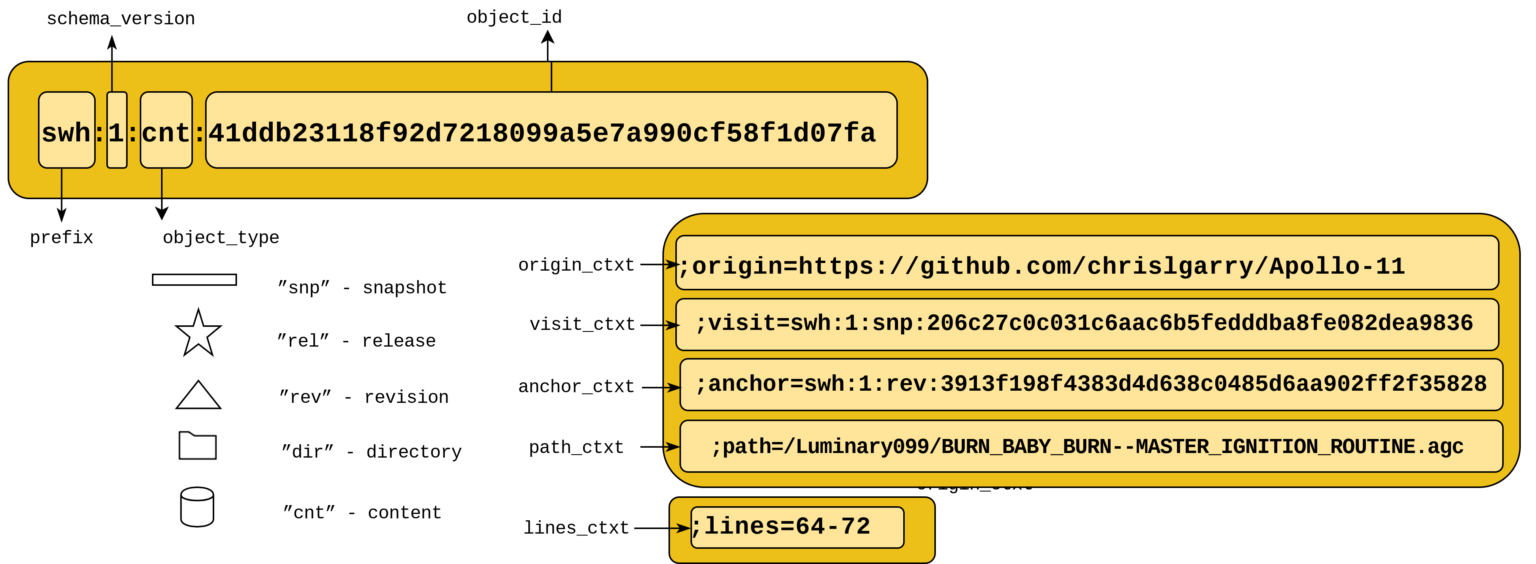
The top yellow box in the diagram corresponds to the « core SWHID. » You can add qualifiers to a core SWHID to specify the location of a software artifact within the Software Heritage Archive or to identify specific code fragments within it.
3.2 What can be identified with a SWHID?
Software can be identified at different levels of detail, ranging from a project’s name to the specific directories and files that make up the code.
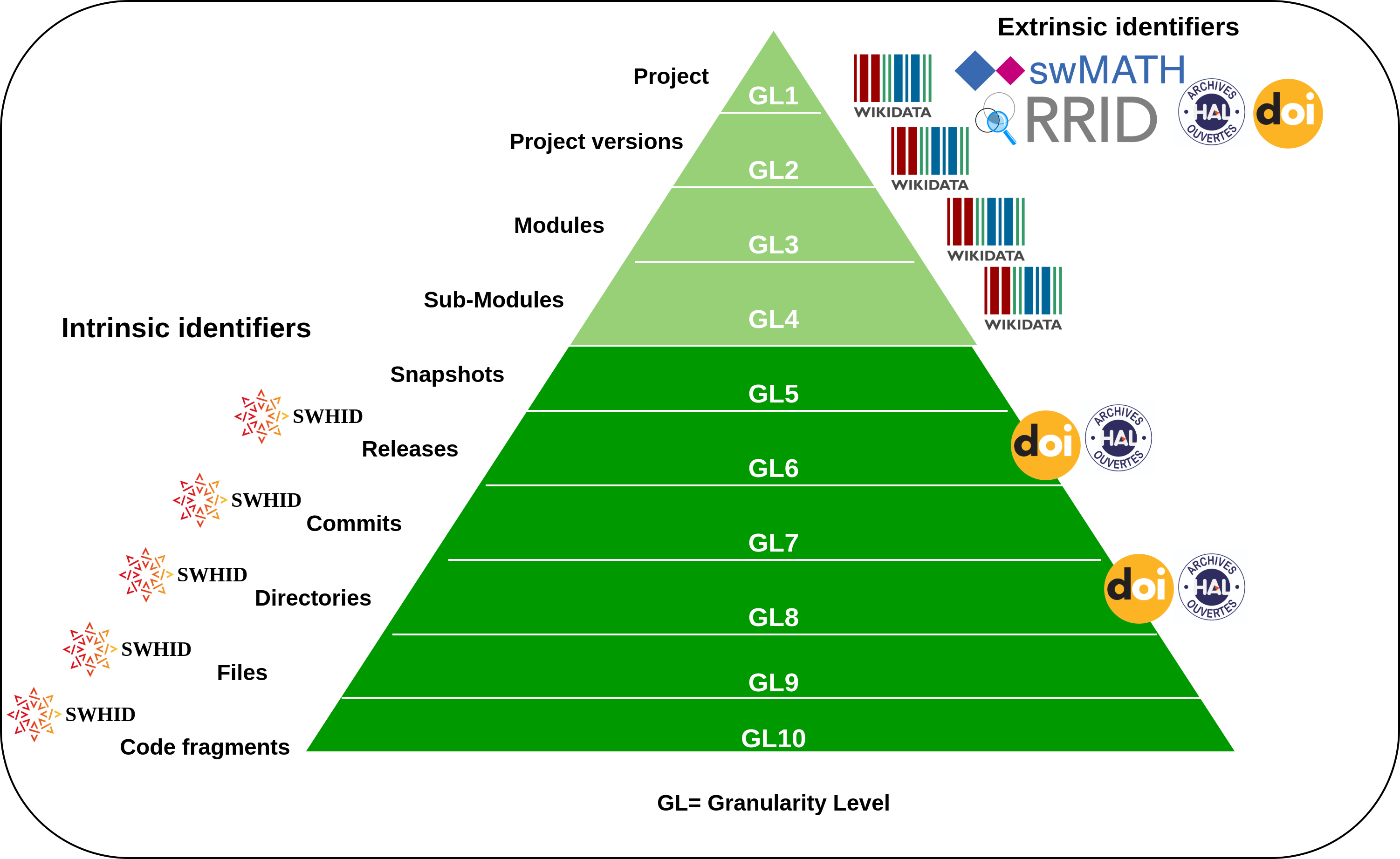
The SWHID is used to permanently identify specific software artifacts. Because the ID is based on the code’s content, it can uniquely reference a snapshot, a release, a commit, a directory, a file, or even a specific code fragment.
Expand for details
A core SWHID can be used to identify the following source code artifacts:
- File contents Example: swh:1:cnt:94a9ed024d3859793618152ea559a168bbcbb5e2 points to the content of a file containing the full text of the GPL3 license
- Directories Example: swh:1:dir:d198bc9d7a6bcf6db04f476d29314f157507d505 points to a directory containing the source code of the Darktable photography application as it was at some point on May 4, 2017
- Revisions (a.k.a commits) Example: swh:1:rev:309cf2674ee7a0749978cf8265ab91a60aea0f7d points to a commit in the development history of Darktable, dated 16 January 2017, that added undo/redo supports for masks
- Releases Example: swh:1:rel:22ece559cc7cc2364edc5e5593d63ae8bd229f9f points to Darktable release 2.3.0, dated 24 December 2016
- Snapshots Example: swh:1:snp:c7c108084bc0bf3d81436bf980b46e98bd338453 points to a snapshot of the entire Darktable Git repository taken on 4 May 2017 from GitHub
Using the lines qualifier, you can also identify code fragments or specific selections of code. For example, use swh:1:cnt:94a9ed024d3859793618152ea559a168bbcbb5e2;lines=4-6 pinpoint lines four to six of the full text of the GPL3 license.
More generally, using a fully qualified SWHID provides all relevant information for placing a software artifact in context. For instance, the SWHID below pinpoints the core mapping algorithm contained in the file parmap.ml, located in the src directory of a specific revision of the Parmap project retrieved from https://github.com/rdicosmo/parmap
3.3 How can I get a SWHID for my software?
Since the core SWHID is an intrinsic identifier, you can compute it for any software artifact locally on your machine. Detailed instructions are available in the documentation.
You can also get the full SWHID for any archived software artifact directly from the Software Heritage Archive: using the red vertical tab called « Permalinks », present on every page that shows source code (see this HOWTO for details). The advantage of this second approach is that you can get a SWHID with relevant contextual information (e.g. the position of your artefact in the global graph of software development).
Expand for details
The « Permalinks » tab provides the SWHID for the content you are viewing. Here’s an example:
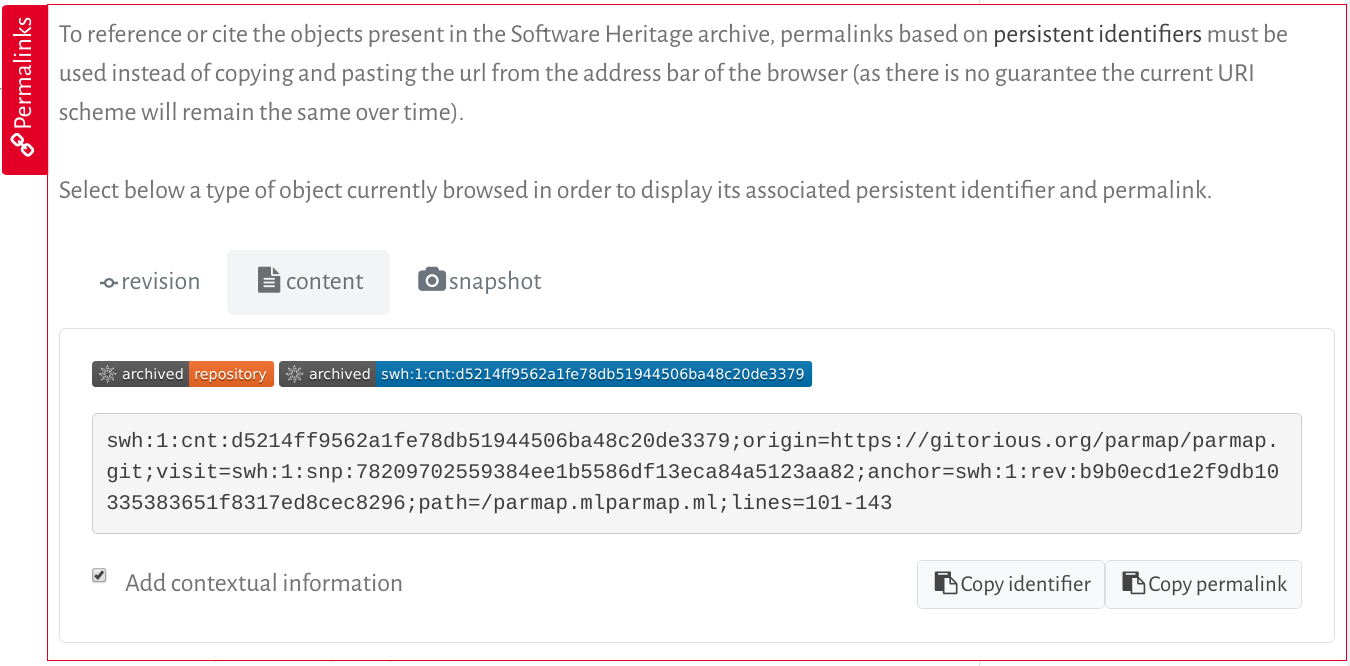
Click « Copy identifier » to get the SWHID in your clipboard. Clicking « Copy permalink » will copy the corresponding URL.
The « Add contextual information » checkbox allows you to choose whether you will get a core SWHID or the SWHID with the extra qualifiers that provide contextual information.
The Permalinks tab offers multiple SWHID options depending on the level of code you need to reference. You can get an ID for a file, a directory, a revision, a release, or an entire snapshot. To find the best option for your use case, see the next question.
3.4 Which type of SWHID should I use in my article/documentation?
The best option depends on your specific needs, but we generally recommend using the full SWHID for a directory. This includes qualifiers that link the directory to its repository and commit, providing full context.
Expand for details
When writing a research article, blog post, or technical documentation, you’ll often face a trade-off: providing a complete reference with the full SWHID or keeping the reference short due to space limitations.
Here’s the recommended best practice for this issue:
- get the full SWHID for the ‘directory’ containing the version of the code you want to reference. Here is an example of such a full SWHID:
swh:1:dir:013573086777370b558b1a9ecb6d0dca9bb8ea18;origin=https://gitlab.com/lemta-rheosol/craft-virtual-dma;visit=swh:1:snp:ef1a939275f05b667e189afbeed5fd59cca51c9d;anchor=swh:1:rev:ad74f6a7f73c7906f9b36ee28dd006231f42552e - ensure the « core SWHID » (
swh:1:dir:013573086777370b558b1a9ecb6d0dca9bb8ea18in the example above) is printed, and the full SWHID is available at least as an hyperlink.
Here’s how to do it in LaTeX:
href{https://archive.softwareheritage.org/swh:1:dir:013573086777370b558b1a9ecb6d0dca9bb8ea18;origin=https://gitlab.com/lemta-rheosol/craft-virtual-dma;visit=swh:1:snp:ef1a939275f05b667e189afbeed5fd59cca51c9d;anchor=swh:1:rev:ad74f6a7f73c7906f9b36ee28dd006231f42552e/}{swh:1:dir:013573086777370b558b1a9ecb6d0dca9bb8ea18}
or in Markdown:
[swh:1:dir:013573086777370b558b1a9ecb6d0dca9bb8ea18](https://archive.softwareheritage.org/swh:1:dir:013573086777370b558b1a9ecb6d0dca9bb8ea18;origin=https://gitlab.com/lemta-rheosol/craft-virtual-dma;visit=swh:1:snp:ef1a939275f05b667e189afbeed5fd59cca51c9d;anchor=swh:1:rev:ad74f6a7f73c7906f9b36ee28dd006231f42552e/)
This approach ensures that readers can find the most useful identifier for reproducibility: the core SWHID of the directory. Because this ID is computed locally from the code’s content, it remains the same regardless of which release or commit the directory belongs to.
In a digital version, the link uses the full SWHID to let readers browse the code in Software Heritage with all of its relevant context, such as its version and origin.
3.5 I want the full SWHID for a source code that’s not already in the archive. How do I do it? How long will it take?
If your code (or the latest version of it) is not yet in the archive, you need to first trigger its archival. This can be done with a « Save Code Now » request or via the deposit API.
After you issue a Save Code Now request, the code is usually processed in a few minutes, depending on the size of the repository. Once the archiving is complete, the request status is updated, and you can get the SWHID.
When a deposit is submitted, the archiving process typically completes in a few minutes. The SWHID is then provided in the SWORD status response.
4. Access and Reuse
4.1 Can I reuse the source code artifacts I find on Software Heritage?
Your right to reuse a software artifact is determined by its license. You must check the license, which is stored alongside the source code, before downloading or using it. If no license information can be found, you should assume you have no right to reuse the code.
Expand for details
All software components present in the Archive may be covered by copyright, or other rights like patents or trademarks. Software Heritage may provide automatically derived information on the software license(s) that may apply to a given software component, but it makes no claim of correctness and the licence information provided does not constitute legal advice. You are solely responsible for determining the license, or other rights that apply to any software component in the Archive, and you must abide by its terms.
4.2 Can I clone a repository using Software Heritage?
Please do not clone a full repository directly from Software Heritage: it is an archive, not a forge. Try first to clone a repository from the place where it is developed: it will be faster and as an added bonus you will be already in the right place to interact with its developers.
Expand for details
Software Heritage stores all the software artifacts in a massive shared Merkle tree, so that exporting (a specific version of) an archived repository implies traversing the graph to get all the relevant contents and packaging them up for your consumption. This operation is much more expensive than downloading an existing tar file or cloning a repository from a forge.
If really Software Heritage is your last resort, and you cannot find the source code of interest elsewhere, we recommend that you download only the version of interest for you, using the « directory » option of the Download button that you find when you browse the archive.
If absolutely needed, you can use the more expensive « revision » option of the Download button, that will prepare for you the equivalent of a git bare clone , which you will be able to use offline. This may require quite some time (hours, or even days for huge repositories).
4.3 Can I retrieve a source code artifact through the API?
Yes, you can. If you have the SWHID at hand, you can use the appropriate API method for it to navigate through the endpoints to follow the graph of project artifacts. Checkout the API documentation for the complete list of endpoints.
Expand for details
- /api/1/snapshot/ which allows you to get the snapshot’s branches and tags, each with a
target_urlkey that contains the URL to - /api/1/release/ or /api/1/revision/ which allow you to get the revision’s or releases’ data. Assuming you get a revision, the
directory_urlkey contains a URL to: - /api/1/directory/ which lists entries of the root directory, with links to other directories and content objects
- /api/1/content/ which returns all the information about a given file content, including a link to the raw data.
You can also lookup an origin, and follow its visits:
- /api/1/origin/search/ allows you to search the exact URL of the code repository
- /api/1/origin/visits/ allows you to list the times Software Heritage visited the repository, and get the snapshot associated with each visit. For each visit, this snapshot is available as a
snapshot_urlkey, that contains the URL to get the corresponding snapshot object.
If you are interested in downloading a large part of the repository (a directory or a set of revisions), you should use the download service called the Vault. The Vault allows you to fetch them in batch and download a tarball. The list of vault endpoints is available at the end of the list of all API endpoints
5. Software metadata
5.1 Can I add metadata to my software?
A regular user can add metadata files in the repository which will be ingested and indexed when using a specific file format (codemeta.json, package.json, pom.xml, etc.).
Expand for details
Follow the Software Heritage guidelines on how to prepare your code for archival.
More information about the formats that are indexed and some general overview of the metadata workflow in the blog-post about mining for software metadata
5.2 What metadata are preserved from a code repository, with save code now?
All metadata contained by the source code repository itself is preserved. This will include the development history and commit dates and messages.
At the moment, other metadata artifacts which are not part of the repository (known as extrinsic metadata) are not preserved when using the Save Code Now feature.
5.3 What metadata are preserved with a deposited software artifact?
All metadata which is sent via the SWORD protocol accompanying the software artifact. For more information visit the deposit documentation.
5.4 What is the codemeta.json file, why should I use it?
As software developers, we may want to provide a machine readable description of our projects, but there are (too) many metadata schemas for describing software, and one can easily get lost.
The CodeMeta initiative created a common vocabulary to address this issue, based on (a slight extension of) the SoftwareApplication and SoftwareSourceCode classes of the well established schema.org initiative, and provides tools to convert back and forth from other metadata schemas.
The codemeta.json file is a JSON-LD representation of the CodeMeta vocabulary, that can be easily created and validated using the Open Source codemeta generator tool. By adding a codemeta.json file to your project, you make it easy to share metadata information, and reduce the burden of retyping a lot of information in data entry forms.
Expand for details
For example, the French HAL national open access archive looks for a codemeta.json file when a software project archived in Software Heritage is deposited, and pre-fills the deposit form using the information it contains, a real time saver!
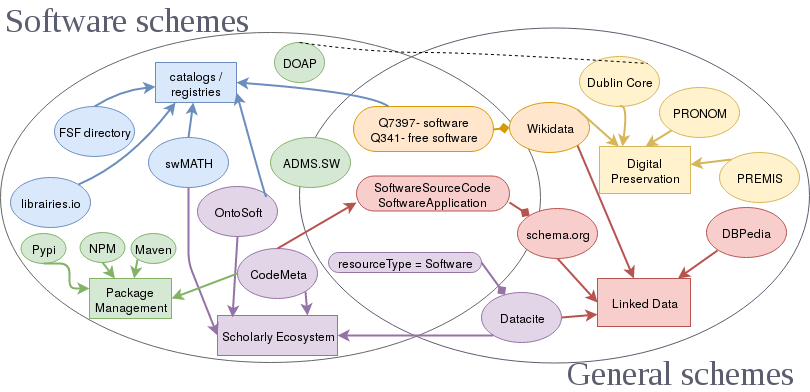
Last but not least, Software Heritage indexes the metadata contained in codemeta.json files and makes it searchable on the web-app using the CodeMeta crosswalk table. The crosswalk table is the Rosetta stone of software metadata, facilitating translation between ontologies and metadata standards for software.
5.5 Does Software Heritage check the metadata (e.g. to verify whether a license is declared)?
The short answer is no. Software Heritage does not perform any a priori filtering of the repositories that are archived.