Listing 47+ million repositories: refactoring our GitHub lister
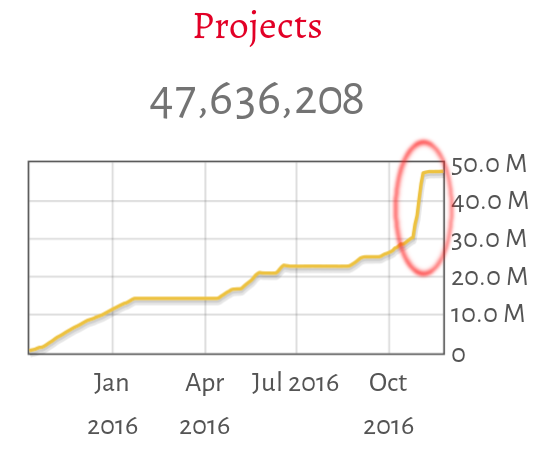
You might have noticed a “slight” bump in the amount of projects referenced on our archive page over the last few days. Did we suddenly uncover a treasure trove of new repositories?
Well, not yet… This bump comes from a change in our process that is a stepping stone towards a more distributed Software Heritage.
Our workflow for collecting and preserving software
We have decoupled the different steps for collecting and preserving software projects:
- listing all the repositories that exists at a given origin (e.g., a forge) → lister component
- scheduling downloads and periodic updates of all the known repositories → scheduler component
- performing downloads/updates of a repository, and injecting all new stuff found there into our archive → loader component
The sudden increase in the number of archived projects (~15 millions more) stems from a change in the way we list repositories in our largest current source of project repositories: GitHub. The way we do things is now generic and the base can be used to do listers for other sources.
Bootstrapping Software Heritage
GitHub is one of the biggest public software development forges in history. We decided to focus our initial preservation efforts on git, and GitHub in particular, as they have become the de-facto standard for modern Free/Open Source Software (FOSS) development. Once we have a proper way of staying up to date with the software that is currently being developed, it will be easier to start looking back at things that don’t move any longer.
One of the first loader components that we have written is hence the Git loader, which takes as argument the URL of a git repository (either remote or on disk) and efficiently loads its contents to the Software Heritage archive.
But the very first component that we had written, even before we had our own hardware or a database schema for the Software Heritage archive, was our lister for GitHub projects. At its core, it’s a very simple thing: it crawls the scrolling API for GitHub repositories, and inserts the received data into a database. This allowed us, slowly, to get a list of all the publicly available GitHub repositories.
Very early, we also wrote a simple recurrent task scheduler, which allows us to run Celery tasks periodically (with an adaptive interval), storing the results asynchronously in a PostgreSQL database.
However, the link between lister, scheduler and loader was manually maintained: the GitHub lister ran a catchup task every day, in Zack‘s crontab on one of our workers, to list the new repositories, those new repos wouldn’t get scheduled until one of us ran through the list and actually updated the scheduler database. We also had no way of disabling updates of repositories that have disappeared. Finally, up until September, we ignored repositories declared as fork on GitHub and only mirror “base” repositories (including all their pending pull requests).
Rethinking the listing of (big) software origins
GitHub has a lot of churn. Of course, lots of repositories are created all the time. But authors sometimes simply remove, rename, or delegate their repositories to other entities, there’s a lot of spam repositories (that get removed pretty quickly), and some repositories get taken down on copyright grounds as well. Therefore, we ended up trying to poll a lot of repositories that don’t exist anymore. Our current stats show 3.7 million dead repos over 48.3 million seen, that is almost 8%.
On the other side of the coin, we had some holes in our (incremental) listing, as some repositories created as private become public. Out of the 800 repositories with more than 10k stars in September 2016, around 100 were not in Software Heritage: new repositories would only be detected if their numeric id was higher than the last repository we had seen. It became clear that listing a big upstream source such as GitHub would need two separate ways of updating:
- do an incremental list of repositories to schedule updates for new repositories early;
- do a full list of all repositories to “fill the blanks” as well as disable disappeared repositories.
Of course, the full list is a very costly operation (with our current settings, it takes about a week using 20 GitHub API tokens), so we need to run it at a lower frequency than incremental listing runs. Those two different tasks are plugged into our scheduler/worker system so the deployment is a breeze.
The main change from our previous way of doing things is that the lister now directly plugs into both the main database as well as the scheduler database: the repositories are recorded inside the main database, and their periodic loading is scheduled as soon as they are detected. When we do a full run of the lister, we remove disabled repositories from the scheduler database so we stop trying to download them as well.
Build your own lister
We focused on GitHub because that’s a big part of FOSS development these days, and we had to focus our limited development resources somewhere. But we know that more and more software is being developed on all the GitLabs out there. BitBucket has a lot of active repositories as well. There are countless different kinds of forges that people are building software on, and we aim to archive them all.
If you want your software archived in Software Heritage, we need to be able to find it, and here’s your opportunity to contribute. We haven’t carved out a stable API yet that allows you to just fill in the blanks, as we only have the GitHub lister currently, and a proven API will emerge organically only once we have some diversity. If you’re a developer with some spare time, and you want the forge of your liking to be archived, please reach out and join our developer community. We’re ready to walk you through the current lister code, and help you adapt it to other forges.
— Nicolas Dandrimont