Browsing the Software Heritage archive: a guided tour
The Software Heritage mission is to collect, preserve, and share the source code from all publicly available software. An important milestone for the project was enabling access and browsing of the Software Heritage archive, and a year ago we made a first step forward by enabling programmatic access via a RESTful API.
On June 7th 2018, at the Unesco headquarters, we were delighted to unveil to the public a web application that provides easy access to the content of the Software Heritage archive, opening the doors of this Library of Alexandria of software source code.
We have been including features aimed at making the archive more accessible to a wider audience, and this blog post will guide you through them.
Source code as a first class citizen
In line with our goal of recognizing software source code as a first class citizen in cultural heritage, we added key features common to many software forge web interfaces such as:
- A search engine of the list of collected software projects (called origins) in order to access their contents;
- Full browsing of a project’s file tree, enabling navigation upward and downward in a hierarchy of directories;
- Proper display of collected source code files (called contents) with syntax highlighting;
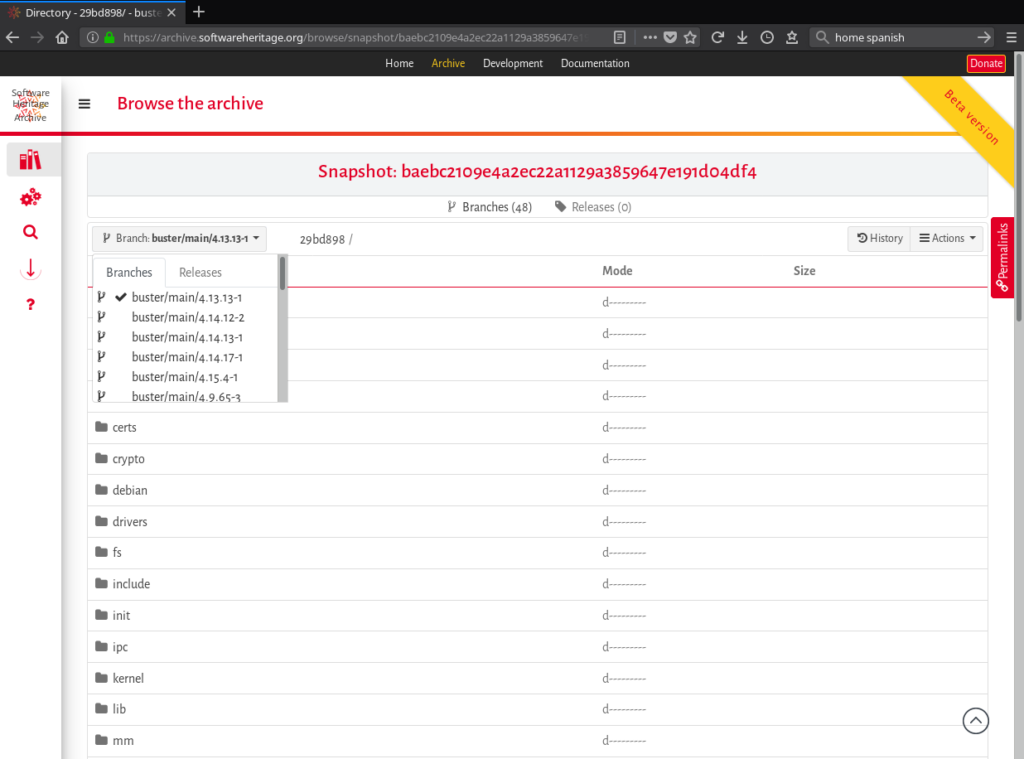
- Easy switching between the different branches of an origin (this set of branches is called a snapshot); and
- Clear presentation of the full development history of an origin trough the chronological display of a list of commits (called revisions).
With software developers in mind, we also created advanced features including:
- The computation and display of the changes between revisions; and
- The display of the history for a particular content.
Finally, to fulfill the mission of Software Heritage, the application also provides the following features:
- A “wayback machine” view, providing the user access to the different snapshots of an origin as they were collected during the different visits performed by the Software Heritage crawlers;
- Interaction with other components of the project like the Software Heritage Vault, enabling users to extract (or cook as we say here) archives from the archive content; and
- A permalinks tab that allows users to easily get the Software Heritage persistent identifiers needed to reference or cite a software source file, revision, release or snapshot.
Current browsing features overview
Since the beginning of development in September 2017, we have experimenting internally a range of features to the browsing interface. Main efforts since then have been made to implement the core browsing features common to web interfaces, available for navigating within source code trees in the Software Heritage archive.
To browse the archive, two different kinds of views are offered: context-independent and context-dependent. To get more details, please refer to the complete URI scheme for SWH Web Browse application.
Context-independent browsing
Context-independent browsing provides information about Software Heritage objects (stored as nodes in the Software Heritage archive Merkle DAG), independent of the contexts where they have been found (e.g., specific repositories, branches, commits, etc). For instance, the following objects can currently be browsed in such a way:
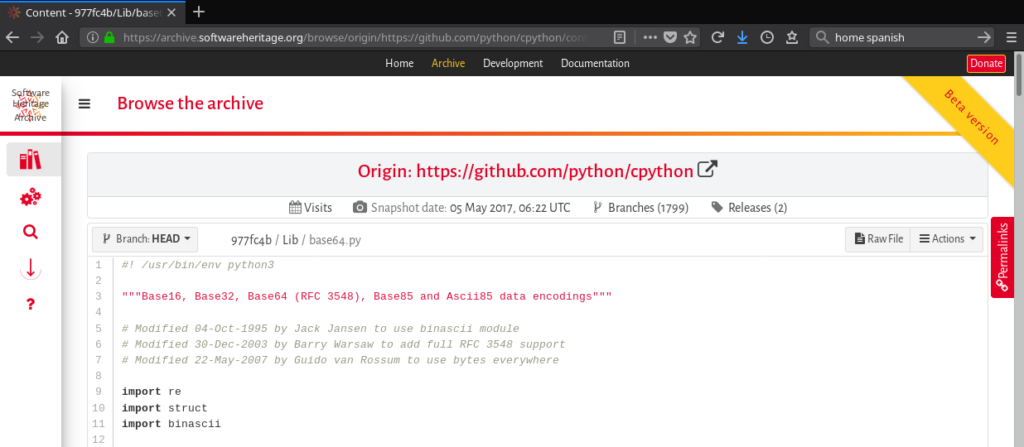
- contents (source files): All source files collected by Software Heritage can be browsed by their checksum values computed using different hashing algorithms (SHA1, SHA256, etc). The corresponding HTML view offers syntax highlighting, display of line numbers and the ability to emphasize a specific block of code.
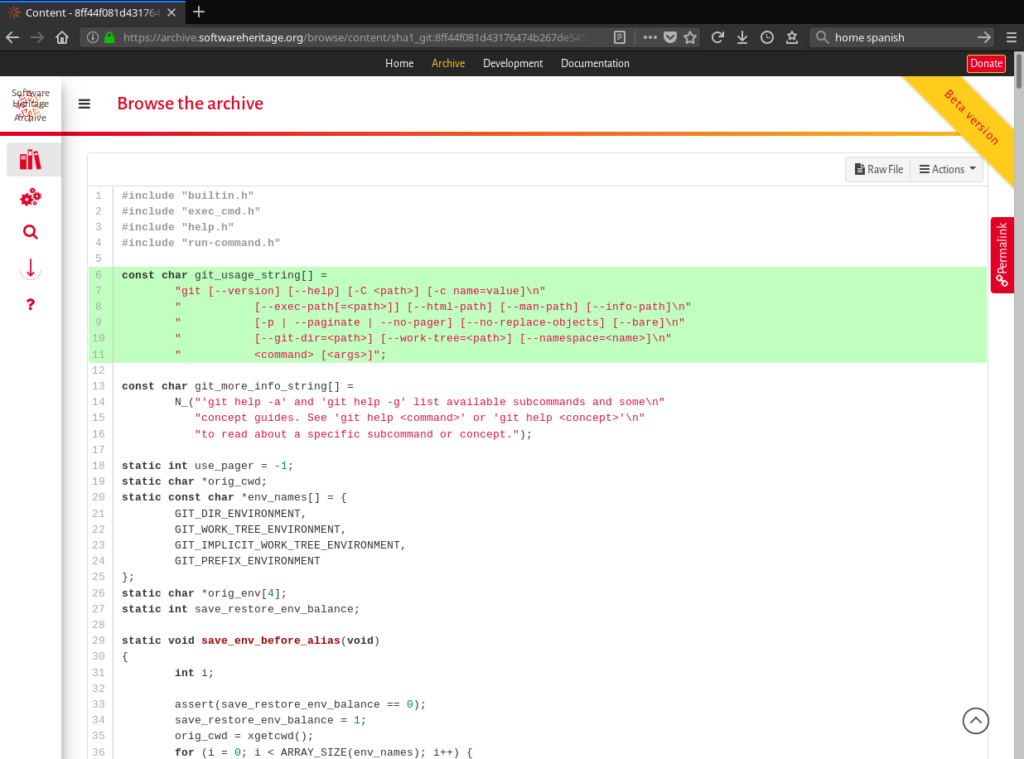
- directories: All directories (referencing contents and other directories) collected by Software Heritage can be browsed using their computed identifier.
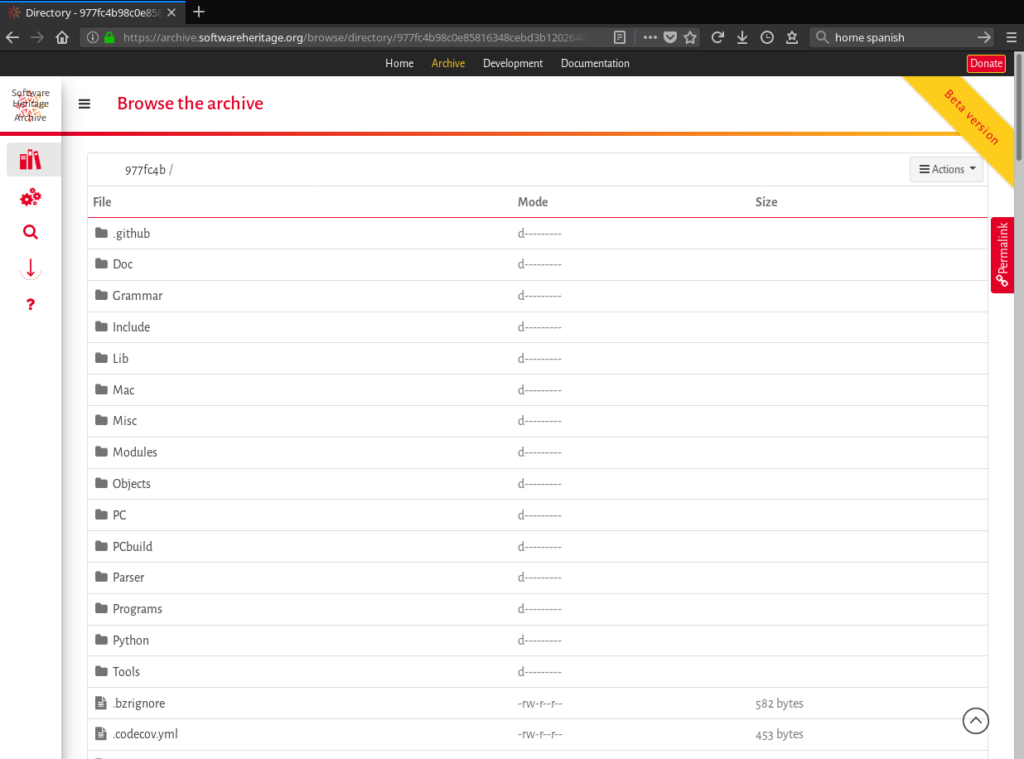
- revisions (commits): All revisions collected by Software Heritage can be browsed using their computed identifier. The corresponding HTML view allows to browse the source tree associated to the revision but also to see the list of file changes and their diffs.
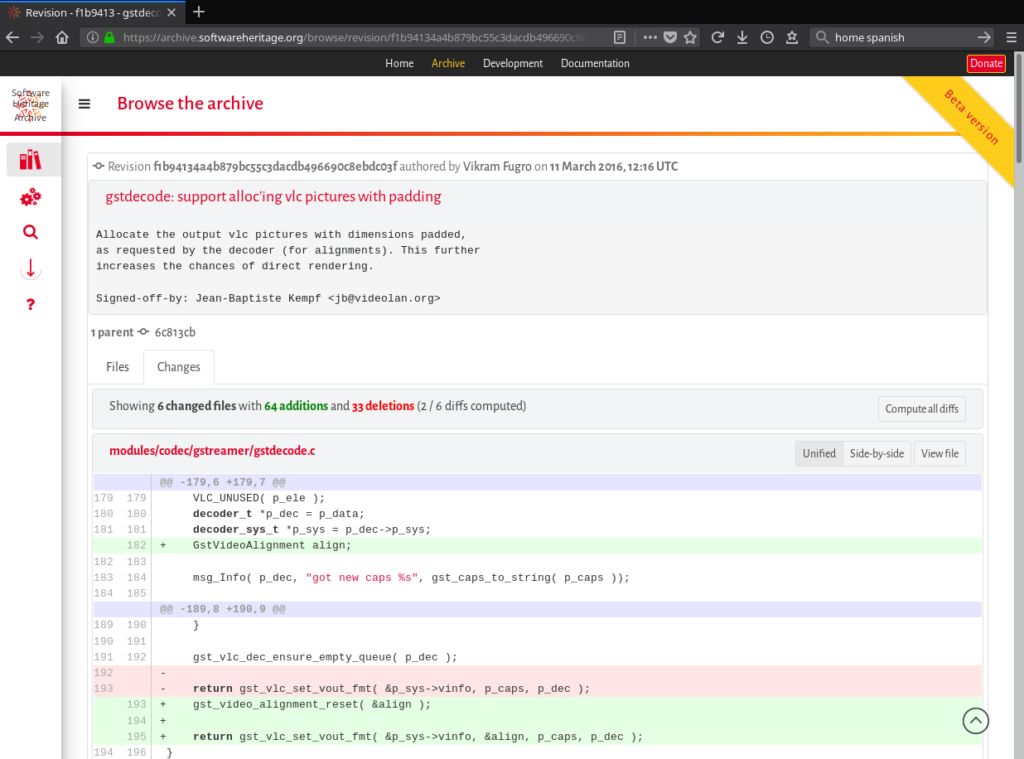
- snapshots (set of branches and releases found during the visit of an origin): All snapshots collected by Software Heritage can be browsed using their computed identifier. The corresponding HTML view enables to easily switch between all the branches and releases contained in a snapshot.
Context-dependent browsing
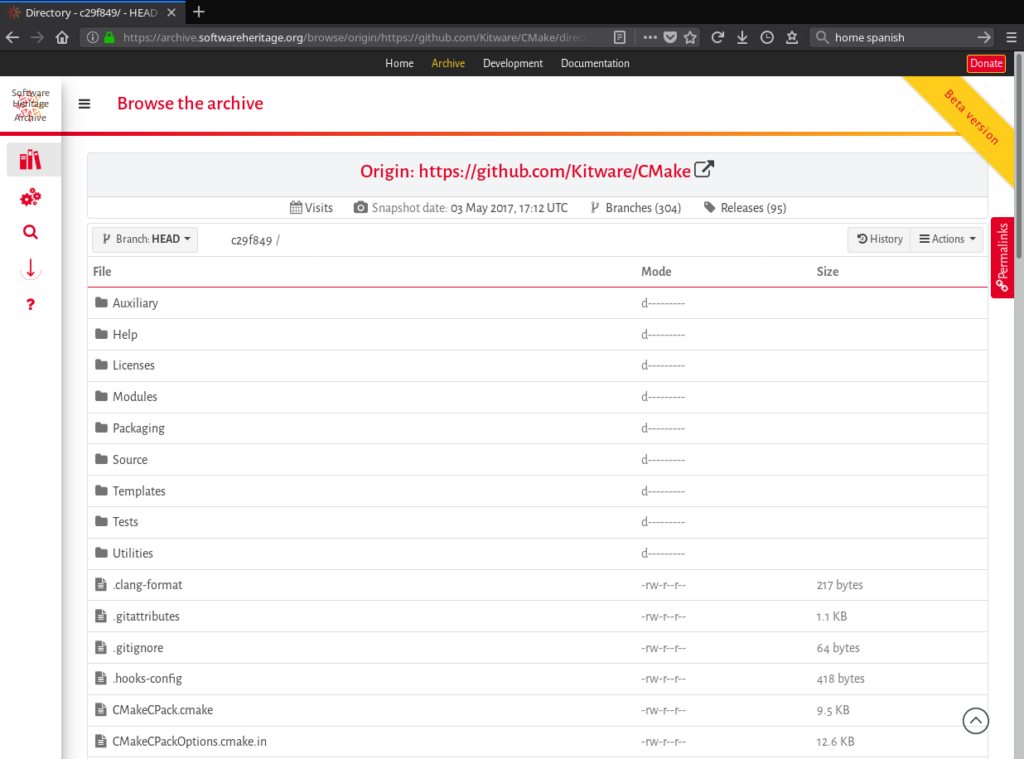
Context-dependent browsing provides information about objects collected by Software Heritage, limited to the specific contexts where the objects have been found. Currently, one can browse Software Heritage objects in the context of an origin. All browsing features introduced above are available in that context, but the displayed software artifacts are those collected from a given software origin during a specific visit from a Software Heritage crawler.
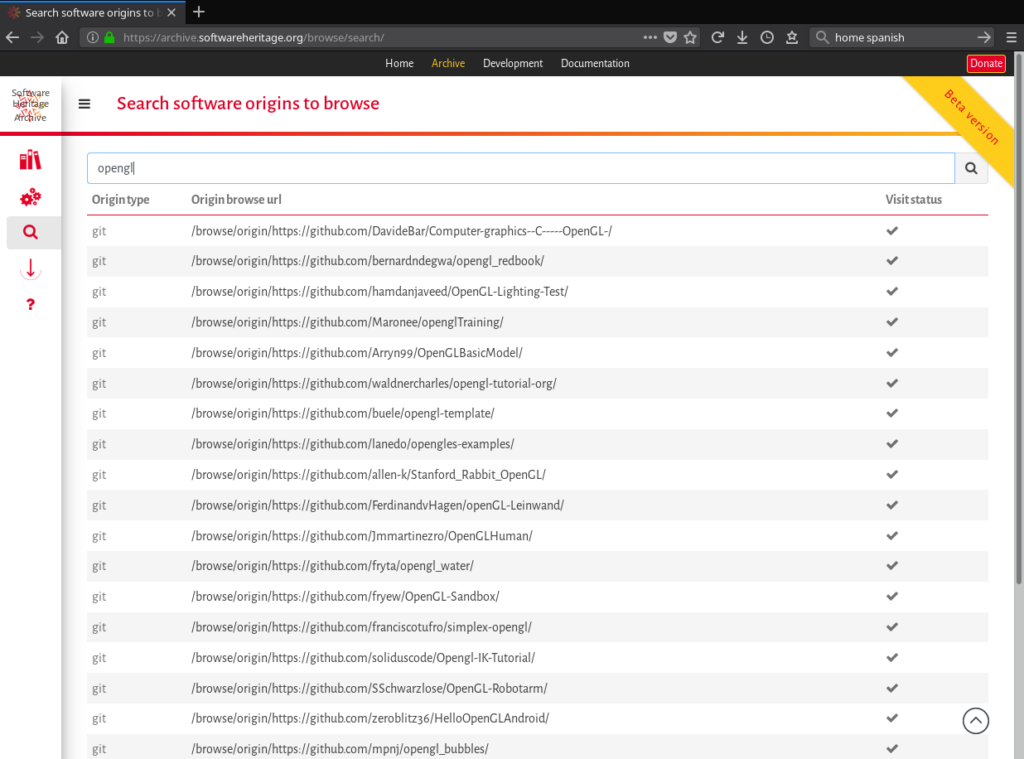
In order to facilitate such a browsing and generate relevant entry points to the archive, an interface is available in order to search for origins visited by the Software Heritage crawlers. Currently, origins can only be searched based on the url they were retrieved from, but more search criteria will be progressively added over time.
Other browsing features
Besides the core browsing features detailed in the previous sections, the Software Heritage web application also offers the following:
- The possibility to download parts of the archive content in self-contained bundles, based on the interaction with the Software Heritage Vault enabling requests to the cooking of directories as tarballs and the reconstruction of a complete git repository from an arbitrary revision;
- The display of the list of revisions heading to a specific one, in other words the commit log;
- The display of various metadata associated to the objects contained in the archive, for instance the computed content checksums;
- The rendering of README files in various formats (Markdown, ReStructuredText) to HTML, in order to better introduce the collected software origins; and
- Various visualizations detailing all the visits performed by the Software Heritage crawlers on a specific software origin, giving the user the ability to use the application as a “wayback machine.”
Technical details and call for contributors
As Software Heritage is developed transparently and collaboratively, all software components are released as Free/Open Source Software (FOSS). Thus, all the source code for the Software Heritage web applications is publicly available in the dedicated swh-web repository hosted on our development forge.
Software Heritage components mainly developed using Python 3. We use the Django web framework for powering the web application on the backend.
For the frontend, we use webpack to bundle the different assets (scripts, stylesheets, etc) served to clients. We rely on well-known web frameworks to implement the graphical interface like Bootstrap or JQuery.
For those interested, you can refer to the modules description of swh-web to get a better understanding of the source code organization.
Conclusion and future directions
The Software Heritage web application gives anyone the ability to freely browse the archive content. At the time of writing that blog post, it gives public access to:
- more than 4 billions source code files
- more than 4 billions directories
- more than 1 billion commits
- more than 80 millions open source projects
Nevertheless, the currently deployed version is still in a beta state, future developments will include:
- Implementation of other developer centric features like the “revision history walk” in order to track the history of a particular content or directory;
- More refined search criteria for origins like the main programming language or the type of open source license used;
- Integration of provenance information for the low level objects (contents, directories, revisions) contained in the archive in order to get all the origins in which those objects have been found; and
- Implementation of an interface to add new origins to the archive for instance by specifying the url of a source code repository to visit.
Contributions to the development of the Software Heritage web applications are also welcome. Please refer to our Development information page and our public wiki for more details.