Mining software metadata for 80 M projects and even more

You can now search archived source code by project metadata.
Navigating through the vast amount of source code archived by Software Heritage can be daunting, and we are working to provide appropriate tools to search inside it. As a first step in this direction, we have been providing you with the possibility to search among the tens of millions of URLs where the source code comes from. This is already quite useful, as these URLs usually contain the project name as well as the name of the hosting organization, but we want more.
The next step has been to make software metadata searchable too. This metadata is extracted from packaging information (as contained in, e.g., package.json, pom.xml, etc.), and is particularly interesting because it is curated by software authors and distributed via forges or repositories, together with the source code.
We are happy to announce that metadata-based search is now available for Software Heritage.
Here is an example: suppose we’re looking for the project where Julien Danjou is involved. Now we can just go to Software Heritage’s search page, type the name in the search bar, tick the “search in metadata” box, press Enter, and we find what we are looking for:
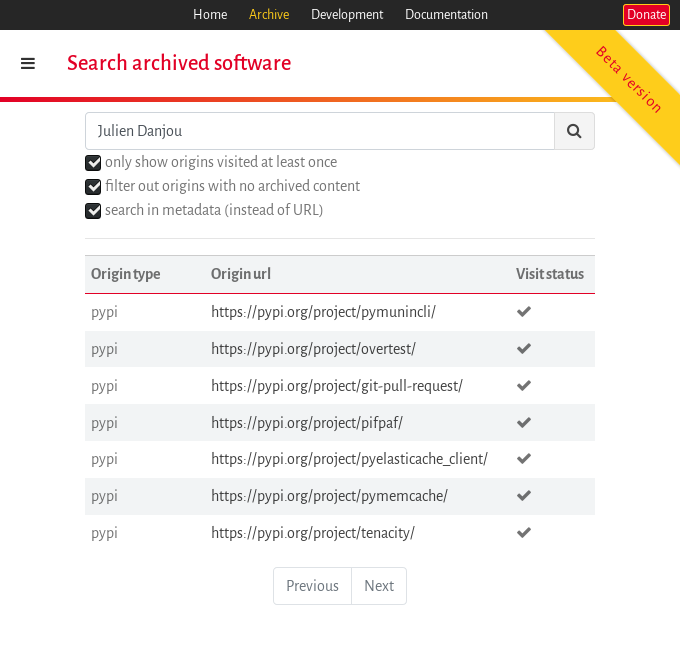
Addressing the metadata heterogeneity challenge.
It seems quite easy, right? But it was actually quite complex to do, because the landscape of software ontologies and metadata standards is quite vast. Various communities have produced different ontologies and vocabularies to describe software and software source code, and different packaging system tend to use different ones.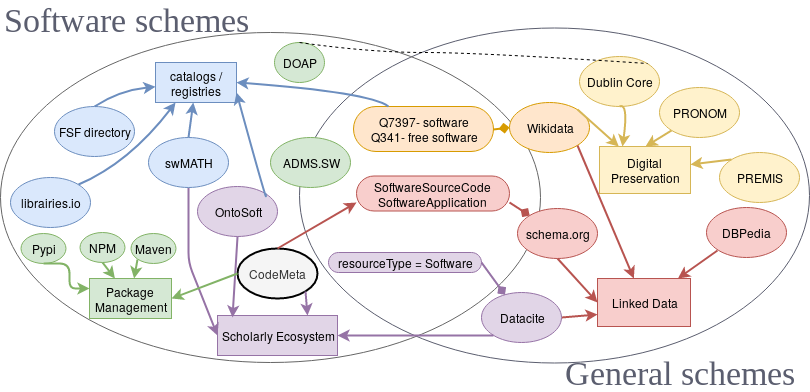
Due to the heterogeneity of the source code archived in Software Heritage, we needed a common vocabulary that encompasses the largest possible amount of software metadata that can be found in the archive, and we wanted to avoid introducing yet another one.
Luckily, this exact problem has been adressed already by the CodeMeta initiative, whose crosswalk table is a kind of Rosetta stone for translating software metadata terminology back and forth into a single vocabulary that is a refinement of the schema.org classes SoftwareApplication and SoftwareSourceCode, providuing a convenient bridge with linked data and the semantic web.
Under the hood
For those of you that are curious about the technical implementation, here is an overview of how all this works. We have created an asynchronous metadata indexing mechanism that sifts through the whole archive for metadata in formats that we can translate to CodeMeta.
For each software origin in the archive, we take its most recent visit and look for the root directory of its “HEAD” revision. If there is a file whose name indicates it is a metadata file (according to filename-based heuristics that can be extended over time), we fetch it, and feed it to the appropriate metadata translator. The resulting (CodeMeta) metadata are stored in a database which can then be queried at search time.
Each metadata translator reads the input file as a dictionary, translates key names following the crosswalk table provided by the CodeMeta Project, and normalizes the results.
For instance, the translator for NPM metadata applies the following steps:
- read a
package.jsonfile - decode the JSON into a Python dictionary
- translate each key using the crosswalk table for NPM
- parse/normalize values from NPM’s specific format into the structure expected by CodeMeta
- convert the obtained dictionary to a CodeMeta object
Only step 4 is specific to NPM, the other ones are shared between all metadata translators. The code to normalize each field is usually rather short, given that it is already designed to be machine-readable. Excluding comments, the NPM metadata translator is only 75 lines of code long, with more than half of the code dedicated to handling the bugs and author fields, which need a more complex handling because they allow more flexible formats.
The currently supported metadata formats are the following: Maven’s pom.xml, NPM’s package.json, Python’s PKG-INFO, and Ruby’s gemspec.
This is just a starting point, and we welcome contributions to support additional metadata formats. We have made available a tutorial on how to add support for additional metadata formats. Thanks to the CodeMeta crosswalk table, there is actually very little you need to do to add support for your preferred format; the NPM translator’s core looks like this:
class NpmMapping(DictMapping, SingleFileMapping):
# load the crosswalk table for NodeJS:
mapping = CROSSWALK_TABLE['NodeJS']
# Define what filename to look for:
filename = b'package.json'
# Define which fields we want to read:
string_fields = ['name', 'version', 'homepage',
'description', 'email']
def translate(self, raw_content):
# Decode the input bytes to a text string:
raw_content = raw_content.decode()
# Load the text string as a JSON object/dictionary:
content_dict = json.loads(raw_content)
# convert the JSON object/dictionary to CodeMeta:
return self._translate_dict(content_dict)
Contribute to the Software Heritage development effort by adding support for additional metadata formats!
— by Morane Gruenpeter and Valentin Lorentz