Intrinsic and Extrinsic identifiers

Building a solid web of knowledge that lasts over time is of paramount importance for academia. A key component of this are the links between the different research outputs, and for this reason references, citations, and various systems of identifiers have been used for centuries, well before the computer era. These systems of identifiers come in two broad categories:
- Extrinsic: use a register to keep the correspondence between the identifier and the object
- Intrinsic: intimately bound to the designated object, they do not need a register, only agreement on a standard
With the web of knowledge becoming massively digital, the need for reliable, long term links between objects has increased, and different communities have focused on different kinds of digital identifiers. On the one hand, in the software development world we have seen over the past twenty years a massive uptake of intrinsic digital identifiers that enable decentralized operations and independent integrity verification. The scholarly communication world, on the other hand, seems to focus exclusively on extrinsic digital identifiers: for example, the Second draft Persistent Identifier (PID) policy [EOSC PID policy 2020] published by the European Open Science Cloud (EOSC) totally ignores intrinsic identifiers, and the advanced services they offer (e.g verification, comparison and reverse lookup).
In order to support reproducible research, and to establish a fluid connection with the software development community, it is important to have intrinsic identifiers properly understood and recognized in the scholarly world, so let’s take the time to look at intrinsic identifiers more closely.
Intrinsic identifiers
Intrinsic identifiers weren’t born in the digital age, and many of us learnt to use them in high school, here are a couple of examples:
- Chemistry:
- we learned in high school that we do not need a register that attributes different identifiers to all possible chemical compounds, it’s enough to learn once and for all the standard nomenclature, which ensures that a spoken or written chemical name leaves no ambiguity concerning which chemical compound the name refers to. For example, the formula for table salt is written NaCl, and read sodium chloride.
- Music:
- we learned in school that to designate without ambiguity all possible musical notes, it’s enough to learn the basic notes and the octaves, or, even better, the scientific pitch notation.
Advantages of intrinsic identifiers
The examples above follow the same common schema: the identifier of the object of interest (a chemical compound, a musical note) is intrinsically related to the object itself and created using a previously agreed upon standard (the chemical nomenclature, the pitch notation).
Researchers all over the world can then reference in their articles any of these objects unambiguously using the reference nomenclature that has been agreed upon beforehand: if a chemist finds a mention of NaCl in an article, one knows it’s salt, and if one finds a grain of salt, one can check that its formula is NaCl; similarly, if a musician sees C0, she knows it’s the first note in the base octave, corresponding to a frequency of 16.352 hertz, and conversely.
Compare with the many examples of extrinsic identifiers we encounter in our everyday life: social security numbers, taxpayer numbers or passport numbers . These identifiers are sequences of digits and/or letters that have little or no relation with the individual to whom they have been attributed. The only way to know who is the person designated by one of these numbers, or to verify that a given person has the identifier she claims, is to consult the authoritative registry. That’s why a registry is such a fundamental component of extrinsic systems of identifiers: if it is corrupted, or get lost, all the system falls into pieces!
Intrinsic systems of identifiers, on the other hand, do not need a register. This carries several advantages: if one has (a copy of) an object, one can gets its identifier from it, without needing any central lookup service, and if one is given an identifier and an object, one can easily verify that they match, without needing to trust any external party. They are independently verifiable, and support decentralized operations.
Intrinsic identifiers in the digital world
With the advent of computers and the Internet, and their skyrocketing adoption, the need to support decentralized operations, enable independent verification, and minimize trusted parties grew quickly. This has led to the widespread adoption of intrinsic identifiers for digital objects, using cryptographically strong hashes that compute a unique digital fingerprint from any digital object, seen as a sequence of bits.
Ralph Merkle showed already in the 1980’s how to use cryptographic hashes to create easily intrinsic identifiers not just for a single digital object, but for arbitrary tree structures (see Merkle trees), and over the last 20 years, these digital intrinsic identifiers have been massively adopted. We find them in distributed file systems like IPFS, in blockchains, and in distributed version control systems like git, mercurial or bazaar, which are essential tools used by tens of millions of software developers worldwide in their daily work to track and manage changes to the source code of software.
In the scholarly world, digital intrinsic identifiers are little known, and the conversation about PIDs have been essentially on register-based, extrinsic systems of identifiers, paying attention to properties like uniqueness, persistence or opacity (we call it abstraction in Computer Science), but ignoring the key properties of independent verifiability and decentralized operations that come with intrinsic identifiers. A detailed analysis of the PID properties that are dealt differently when using intrinsic identifiers w.r.t extrinsic identifiers can be found in [Di Cosmo et al. 2018] and [Di Cosmo et al. 2020] .
SWHIDs: cryptographic hashes for long term preservation
Software Heritage computes and exposes the SWHID intrinsic identifier for each of the more than 20 billion software artifacts preserved in the Software Heritage archive.
As shown in the picture below, the core of a SWHID identifier is made up by a prefix, swh (registered with IANA), a schema version, a tag to identify the type of the artifact it denotes (snapshot, release, revision, directory or content), and the cryptographic hash of the corresponding object, computed like for Merkle trees. Given a software artifact, everybody can compute the corresponding SWHID using a standard cryptographic algorithm, and can verify that it has not been modified.
The SWHID
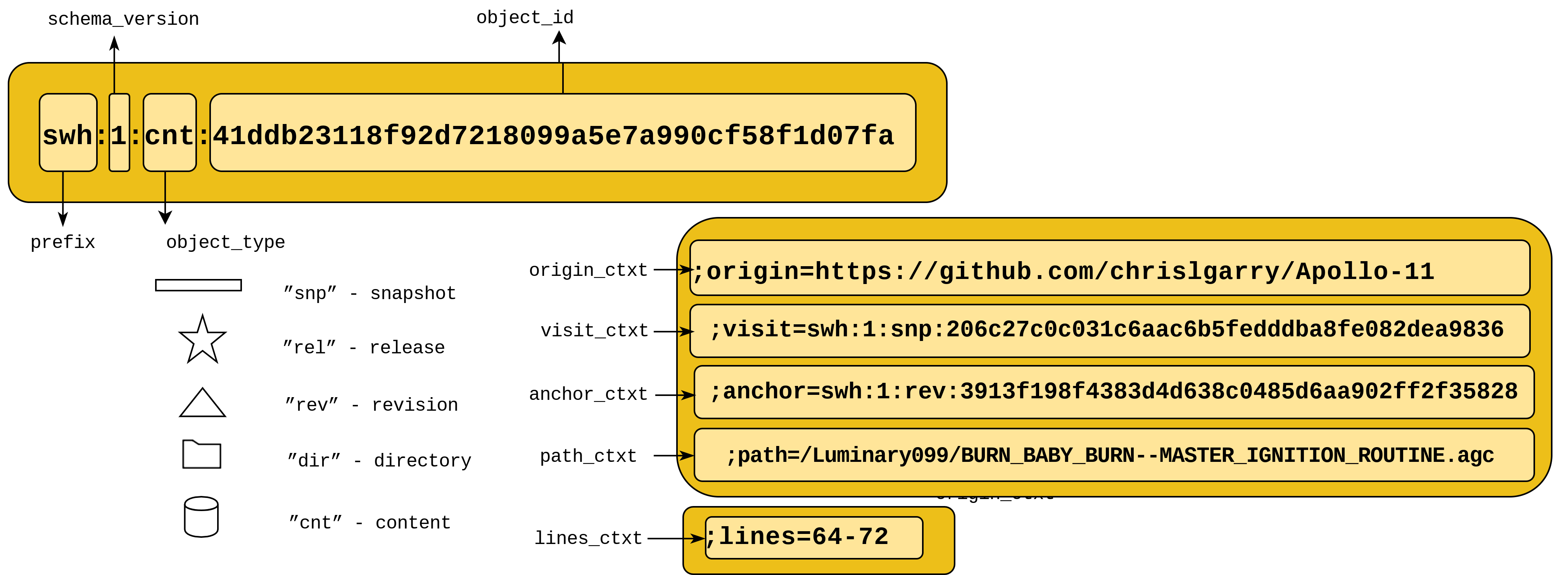
A core SWHID identifier can also be equipped with qualifiers that provide extra information about the context where the software artifact is expected to be seen, like the URL of the origin from which it was retrieved, the path and file name, etc.
Here are a few examples, click on the links to access the corresponding archived source code:
- fragment of Apollo 11 source code: turn around the LEM swh:1:cnt:0c1741c1fb0150f111625d02277407f628c31bac;origin=https://github.com/virtualagc/virtualagc;visit=swh:1:snp:cdcd2bc43331a436e8c659ba93175ef7d7eb339b;anchor=swh:1:rev:4e5d304eb7cd5589b924ffb8b423b6f15511b35d;path=/Luminary116/THE_LUNAR_LANDING.agc;lines=244-260/
- fragment of Quake III source code: reverse square root swh:1:cnt:bb0faf6919fc60636b2696f32ec9b3c2adb247fe;origin=https://github.com/id-Software/Quake-III-Arena;visit=swh:1:snp:687ac8cdbfab3b78b7f301abee5f451127f135fc;anchor=swh:1:rev:dbe4ddb10315479fc00086f08e25d968b4b43c49;path=/;lines=549-572/
We refer the interested reader to [Di Cosmo et al. 2018] and [Di Cosmo et al. 2020] for a discussion on the SWHIDs in an academic ecosystem; detailed usage guidelines for researchers are available too.
Combining intrinsic and extrinsic identifiers for academic software
The joint RDA & FORCE11 Software Source Code Identification Working Group (SCID WG) has reviewed during the past year identification use cases and identifier schemes for software to analyze what identifier fits best for which software target (project, module, version, etc.), which are specified in the recently published first draft.
The working group identified, analyzed and classified the use cases in these four different actions:
- archiving,
- referencing,
- describing
- and receiving/giving credit.
The main realization is that one type of identifier can’t answer all use cases, we need both intrinsic identifiers and extrinsic identifiers for software research outputs.
You are welcome to check out the output and comment the first version on the community review document.
[update]
The output mentioned above is now published:
Research Data Alliance/FORCE11 Software Source Code Identification WG, Allen, A., Bandrowski, A., Chan, P., Di Cosmo, R., Fenner, M., Garcia, L., Gruenpeter, M., Jones, C. M., Katz, D. S., Kunze, J., Schubotz, M. & Todorov, I. T. (2020). Use cases and identifier schemes for persistent software source code identification (V1.1). Research Data Alliance. https://doi.org/10.15497/RDA00053
References
[EOSC PID policy 2020] Hellström, Maggie, Heughebaert, André, Kotarski, Rachael, Manghi, Paolo, Matthews, Brian, Ritz, Raphael, … Wittenburg, Peter. (2020, May 1). Second draft Persistent Identifier (PID) policy for the European Open Science Cloud (EOSC) (Version 2.0). Zenodo. http://doi.org/10.5281/zenodo.3780423
[Di Cosmo et al. 2018] Di Cosmo, R., Gruenpeter, M., & Zacchiroli, S.. Identifiers for Digital Objects: the Case of Software Source Code Preservation. iPRES 2018 – 15th International Conference on Digital Preservation, Sep 2018, Boston, United States. pp.1-9, ⟨10.17605/OSF.IO/KDE56⟩. ⟨hal-01865790v4⟩
[Di Cosmo et al. 2020] Di Cosmo, R., Gruenpeter, M., & Zacchiroli, S. (2020). Referencing Source Code Artifacts : A Separate Concern in Software Citation. Computing in Science & Engineering. (10.1109/MCSE.2019.2963148). (hal-02446202)