Deep Dive into the archival of Software Metadata

Software metadata is vital for the classification, curation, and sharing of free and open-source software (FOSS). In a recent presentation at the Software Heritage Ambassador’s plenary, Morane Gruenpeter and Valentin Lorentz discussed the collection, preservation, and sharing of software metadata to build the semantic web of FOSS.
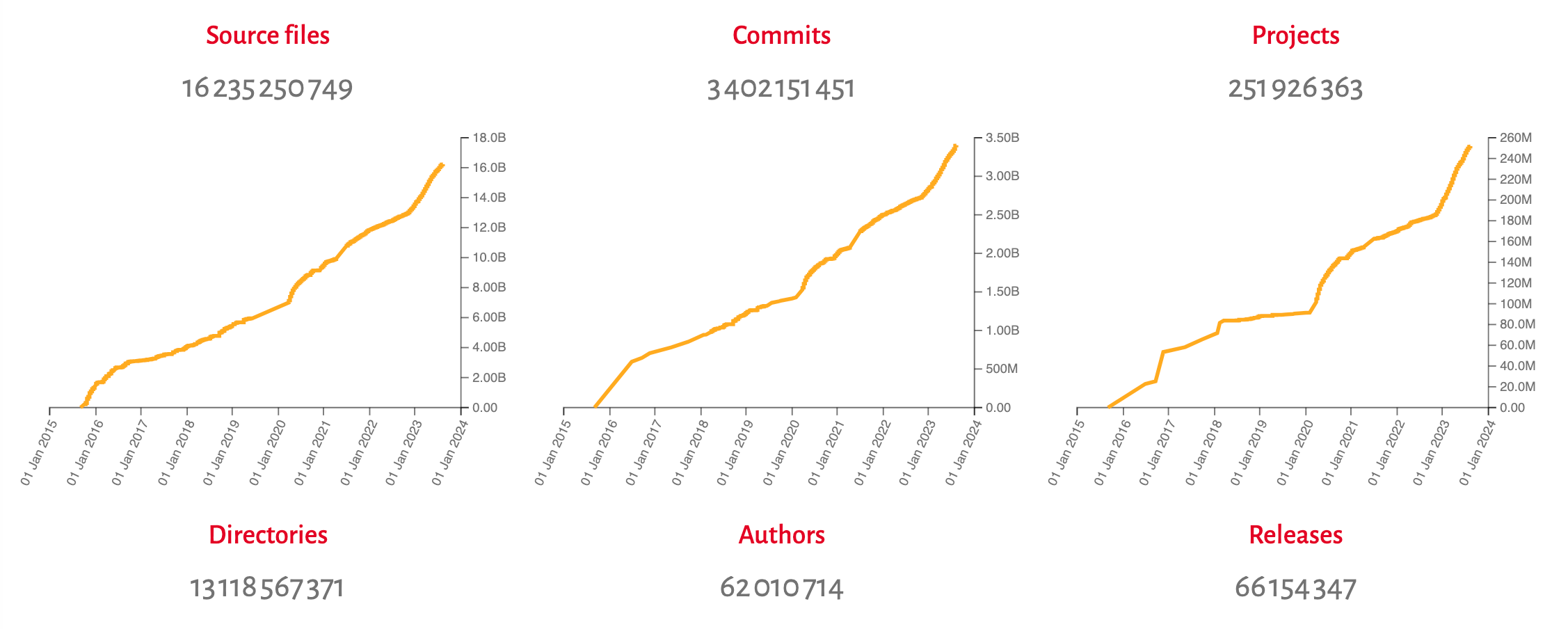
Software Heritage aims to collect, preserve and share the software commons from various sources, with the goal of creating the universal source code archive. Currently, the archive holds over 251 million projects and more than 16 billion unique source code files. However, since the same source code can be collected from different origins, there can be variations in the accompanying metadata, which describe the projects.
Navigating the metadata maze
To navigate this diverse source code landscape, relevant metadata becomes crucial. Different projects may use different terms, vocabularies, and ontologies to describe themselves. By generating linked data and referencing source code artifacts within the Software Heritage archive, there is potential to create a “semantic Wikipedia” of software.
Analyzing the existing metadata landscape reveals various sources, including catalogues, repositories, platforms, and package managers like ASCL, swMath, OpenAire, libraries.io, Zenodo, HAL, GitHub, PyPI, NPM and many more.
There are two sources of extraction for metadata, which can be either intrinsic or extrinsic to the source code
The embbeded metadata, a.k.a intrinsic metadata
Intrinsic metadata refers to information within the source code itself, such as README files, licenses, and package management files. It can be human-readable (README) or machine-actionable (codemeta.json), offering accuracy and longevity but relying on the author’s knowledge.
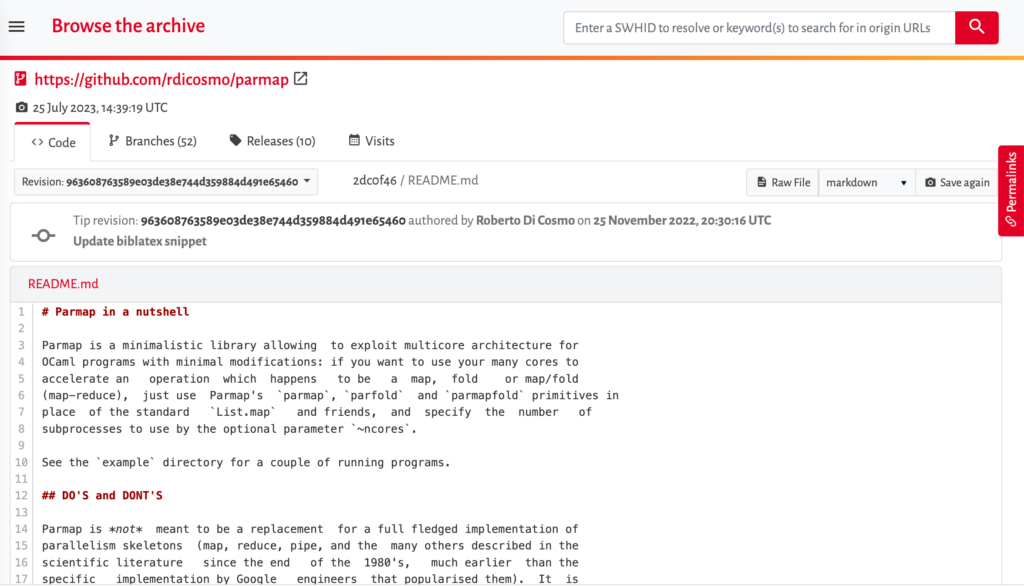
An example of a human-readable file, a README file, from the Parmap software project: swh:1:cnt:43243e2ae91a64e252170cd922718e8c2af323b6
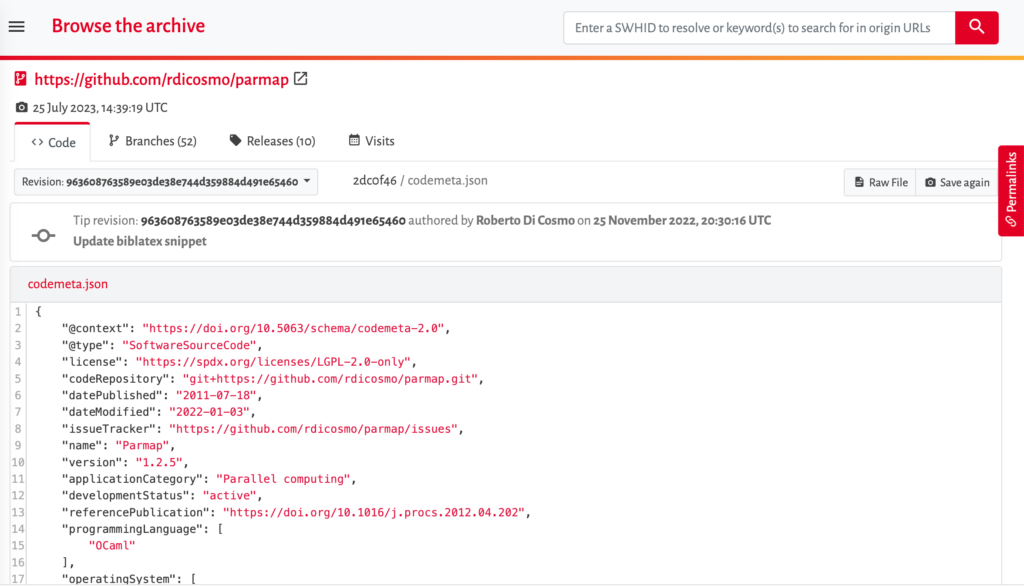
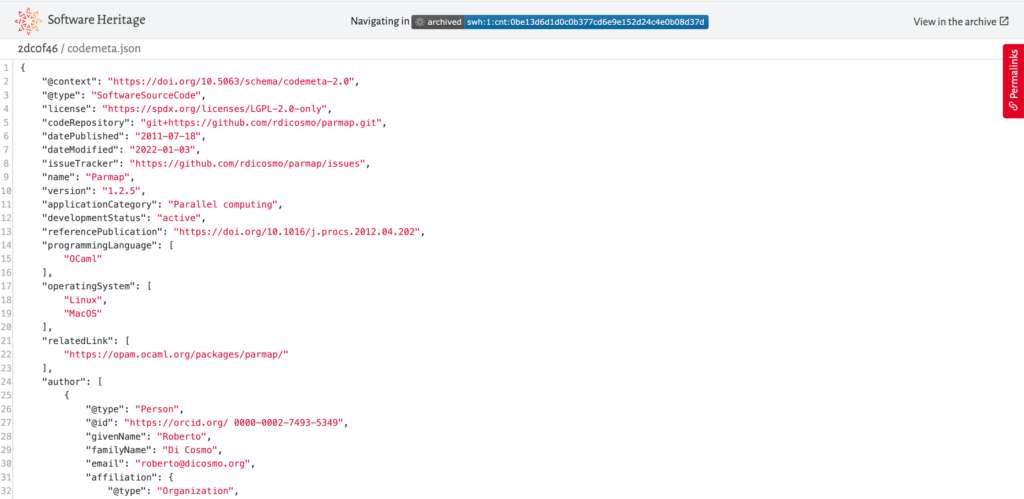
An example of a machine-actionable metadata file, a codemeta.json file, from the Parmap software project:
swh:1:cnt:0be13d6d1d0c0b377cd6e9e152d24c4e0b08d37d
The external metadata, a.k.a extrinsic metadata
Extrinsic metadata refers to metadata records on external entities like code hosting platforms, registries or scholarly repositories keeping additional information about the Software. Curating the software source code’s metadata while archiving it is a good approach to ensure accuracy and completeness. For example, the HAL French national archive provides a moderation workflow to verify the metadata compatibility with the software artifacts. Below you can see a full metadata record as captured on the HAL platform:
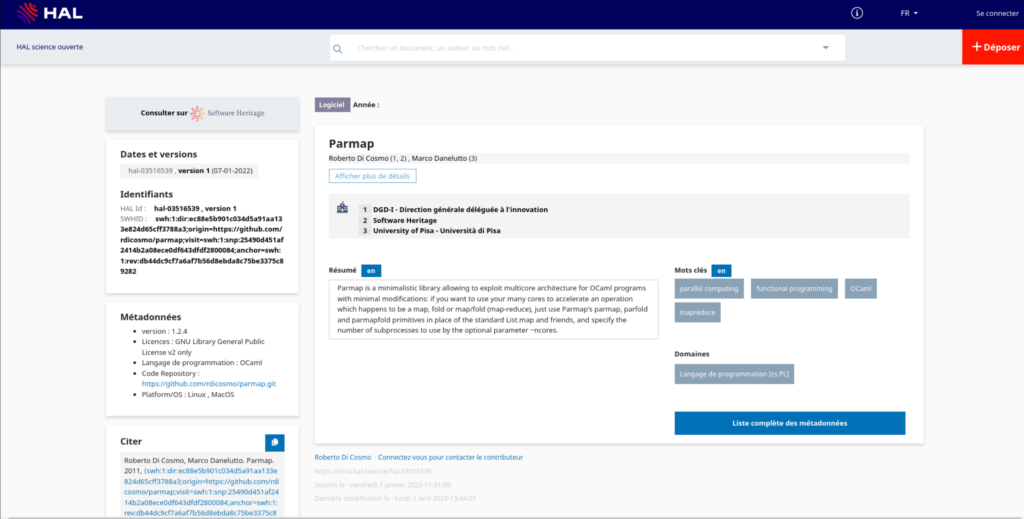
For more information about the HAL-SWH integration, you can read the blog post and watch the tutorials.
Translating metadata with CodeMeta
The CodeMeta vocabulary, a subset of schema.org, facilitates interoperability and consistency in software metadata. It acts as a common vocabulary, and the community is encouraged to contribute to the discussion in the CodeMeta repository.
It’s key addition is the crosswalk table that provides mappings to many software vocabularies. With the CodeMeta crosswalk table, indexing becomes possible.
Unravelling the Process: From Collection to Indexing
Behind the scenes, there is a well-oiled machine that facilitates the storage and indexing of metadata, enabling search possibilities and promoting the discoverability of software.
In this system, two types of metadata are managed. The first type, intrinsic metadata, is stored alongside the code in the main storage. The second type, extrinsic metadata, is archived separately in the Raw Extrinsic Metadata Storage.
To effectively index the metadata, a translator is utilized to convert it into CodeMeta format. The resulting indexed metadata is then stored in a dedicated location called the Indexed Metadata Storage.
For a more comprehensive understanding of this workflow, you can refer to Software Heritage’s documentation.
Below is a diagram depicting the complete workflow, encompassing the steps to collect, preserve, index, and share metadata:
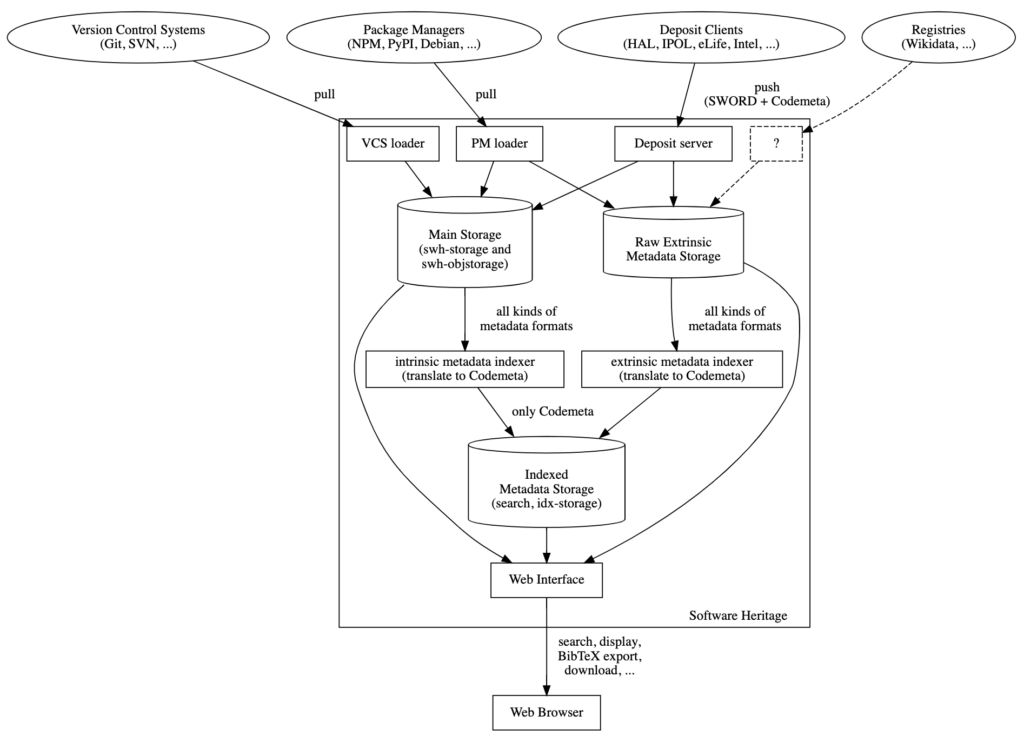
By following this workflow, the system can efficiently manage and make accessible the metadata associated with various software, helping in the discovery and sharing of valuable code and related information.
The metadata use cases on the Software Heritage web-app
Presenting software metadata effectively on web interfaces is crucial. Intrinsic and extrinsic metadata, as well as specific properties like citations, need to be showcased. Software Heritage’s roadmap includes plans for metadata presentation.
One of the key principles of Software Heritage is to include and present only “facts” in its knowledge base. However, this principle becomes challenging when dealing with metadata due to the subjective nature of such information. Translating metadata semantically, in order to harmonize the diversity, can also introduce qualitative interpretation issues. Mapping terms and information can be susceptible to misinterpretation and loss of meaning during the translation process.
For example, in Python PKG-INFO, there are two properties `summary` and `description` that are mapped to the `description` property in the CodeMeta crosswalk table. This is not the only example where vocabularies introduce different and yet similar terms to semantically describe different aspects.
In the coming months, we will collect use cases from the community to better understand the software metadata needs.
You are invited to share your use case via the issues on the *use cases repository* to facilitate analysis of these use cases by the SWH team.
We hope that the collaborative efforts of the Software Heritage community and user involvement will lead to a more interconnected and discoverable FOSS ecosystem.