How Software Heritage ensures reliable Guix deployment
Reproducibility in research is a growing challenge. After researchers publish their findings, the underlying software — the source code that drives their results — often disappears or becomes unusable over time. This makes verifying and building upon past work incredibly difficult.
For Simon Tournier, a research engineer at Université Paris Cité, the complexity of bioinformatics software was a constant battle. As a member of the Saint Louis Core Facilities team, he deals with various specialized workflows. Struggling to manage the intricate web of dependencies, from laptop to cluster, Tournier discovered GNU Guix, which helps in composing these computational environments. Now, he considers Guix indispensable for reproducible deployments, a critical component of reproducible research and Open Science.
His talk at FOSDEM offered a practical perspective, exploring five years of work on this critical problem. It’s the output of a joint effort between Guix contributors and the Software Heritage team. (He kicked off the talk by thanking Antoine R. Dumont, Antoine Eiche, Antoine Lambert, Ludovic Courtès, Stefano Zacchiroli, and Timothy Sample.)
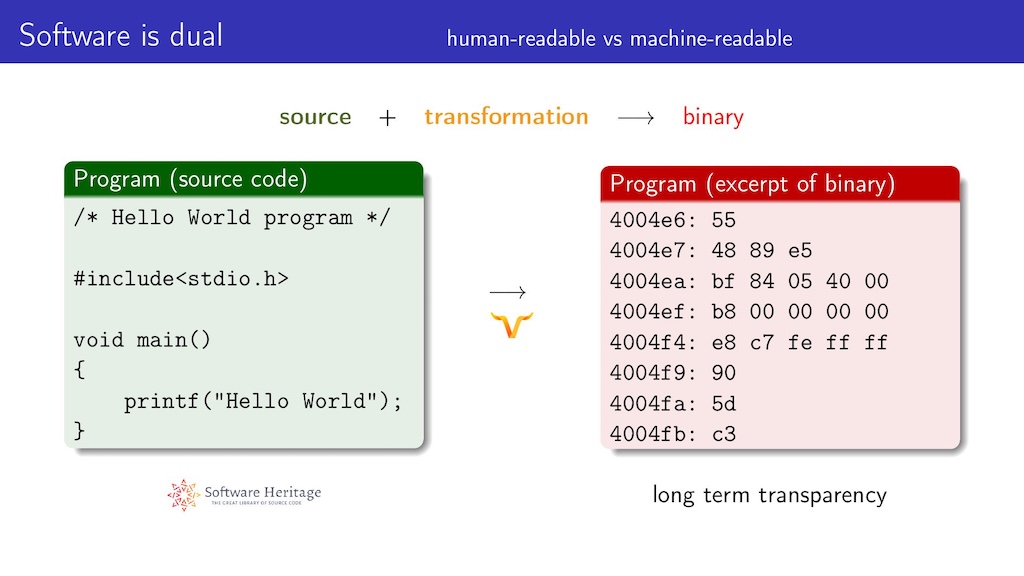
The dual nature of software creates a challenge: humans read source code, while machines execute binaries. The tricky part? How binaries are produced from source code. For example, compilers or interpreters transform source code into something hard to decipher just by looking at the binary. Since Reproducible Research is built on the top of full transparency, reproducible deployments require both source code and transformation; both are crucial. Software Heritage provides the means to audit and verify original source code, and Guix offers the capability to audit and verify the process of transforming that code into binaries.
Credit: Simon Tournier
The challenge of reproducibility
Imagine this: Alice publishes her research in 2022, sharing her code, made with version 0.9 of the software. A few years later, Blake tries to reproduce Alice’s results. Version 1.2 is readily available, but the outcomes differ. Even after finding and installing version 0.9, when Blake tries to recreate the original results, things don’t match up. Why? Because Blake doesn’t fully control all the variables in the original computing environment. To address this, it’s crucial to identify these variables: the specific code used, the tools required to build the source code, the tools needed to run the compiled binary, and all the dependencies; i.e., there are four identifications for each tool of the workflow and recursively for each dependency.
Package managers and Guix
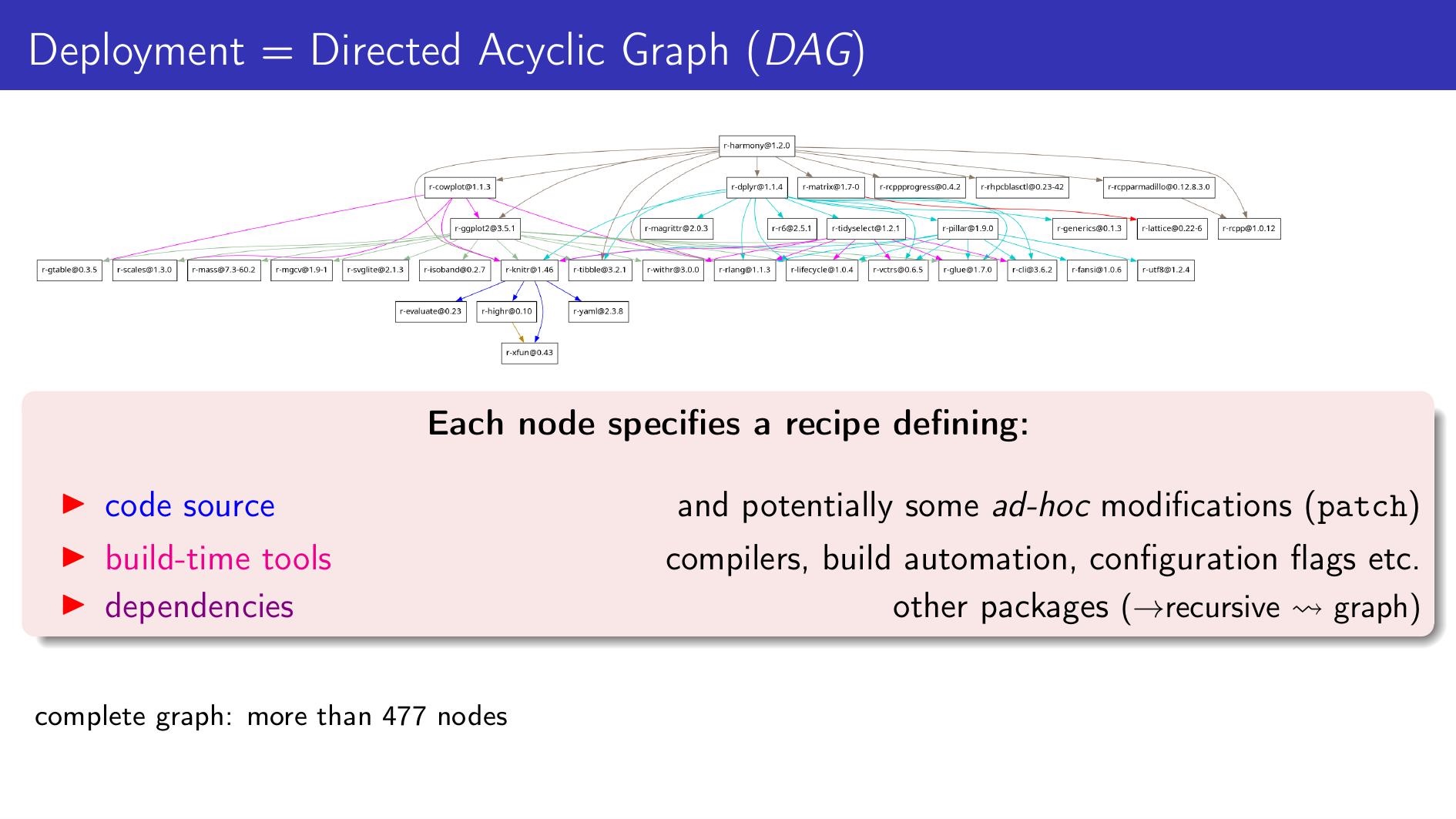
The problem isn’t new; that’s the job of package managers, e.g., Conda, APT, Brew, etc. Deploying a computational environment essentially involves deploying a dependency graph, and package managers are the tools that manage this graph. Each node of the graph represents source code and all the various parameters to configure, compile, and build the source code, while edges describe the dependencies. For instance, installing a package like “harmony” for processing biological sequencing data using the R language can involve a graph of approximately 500 nodes.
Credit: Simon Tournier
Guix can be seen as a package manager. The main difference between Guix, which has a software deployment model based on the same principles as Nix, and the other package managers is how this graph is described and how the graph of dependencies is handled. Contrary to other package managers, where the graph is dynamically resolved from the constraints of the version specifications, Guix provides revisions that specify one unambiguous graph. A Guix revision pins a complete collection of packages and Guix itself.
When Alice says “I used this tool at version 0.9”, it implicitly means Alice used a whole specific graph of dependencies. That means that Blake needs this same dependency graph to reproduce, audit, or verify the environment. Using Guix, Alice provides the Guix revision (e.g., EB34FF1), which encapsulates the tool at version 0.9 and all the dependencies, including the options for configuring, compiling, and building. Now Blake can use this revision to redeploy the same bit-to-bit computational environment, ensuring transparency and verifiability.
The deployment model works under two assumptions: deterministic builds and publicly available source code. When building all the nodes of the graph, they must be deterministic. It’s more challenging than it might appear at first, and we are very grateful for the effort led by the project Reproducible Builds. And, to reproduce or audit a deployment, all necessary source code (remember, e.g., 500 packages) must be accessible.
Enter Software Heritage
Source code disappearing from the internet is a real problem. This link rot is a significant challenge, which is why the first mission of Software Heritage is to collect and preserve source code. Today, it’s the largest publicly available archive of software source code.
A substantial percentage of source code is missing from its original location. Considering Guix as an example, by 2024, around 3.6 percent of source code from 2022 is already missing, and the situation is worse and worse when going back further in the past: about 8 percent of source code packaged by Guix five years ago is now unreachable from its original location. Moreover, the loss of only one package can have cascading effects due to dependencies; the disappearance of one package, like OpenJDK, can result in the loss of hundreds of dependent packages, not just one.
“Science is building on sand. Research projects are created, papers are published, and the source code is just disappearing from the internet; that’s why we need Software Heritage,”
Simon Tournier
A story about content-addressed identifiers
Software Heritage uses intrinsic identifiers, much like checksums, to identify source code. This method guarantees that the identifier points directly to the content, allowing for precise referencing of individual files, snapshots, releases, revisions, directories, and other elements. The Software Hash IDentifier (SWHID), a universal identifier for software pioneered by Software Heritage, is officially the ISO/IEC international standard 18670. Software Hash IDentifiers (SWHID), which are now an ISO standard with specifications available at swhid.org, function as content-addressed identifiers.
On the other hand, Guix also employs an intrinsic identifier to identify source code; the format is Normalized ARchived (NAR), inherited from Nix. Once packaged by Guix, the source code is “essentially” content-addressed. Specifically, if a source code location becomes stale, e.g., the URL is no longer available or does not serve the exact same source code, then the user can manually provide the new URL, and Guix proceeds. Or Guix can automatically check and download if a copy is available on alternative locations like those provided by the Guix project, the Nix project, or Software Heritage. The automation relies on a bridge provided by Software Heritage between the different content-addressed identifiers: SWHID for one, NAR for the other.
Hold on, a lot of packages depend on compressed tarballs, and Software Heritage archives software as source code, doesn’t it? Indeed, compressed tarballs pose a unique challenge because, in addition to source code, they require metadata to be rebuilt bit-for-bit. For example, different compression levels produce different checksums, which undermines a content-addressed system.
This is where the Disarchive tool comes in. Timothy Sample designed it to disassemble the compressed tarball and extract all the metadata, such as compression level, timestamps, etc. These metadata are stored in a dedicated Disarchive database hosted by the Guix project, while the data itself (plain source code) is archived in Software Heritage. On request, Disarchive can assemble the metadata and data and then output the bit-identical compressed tarball.
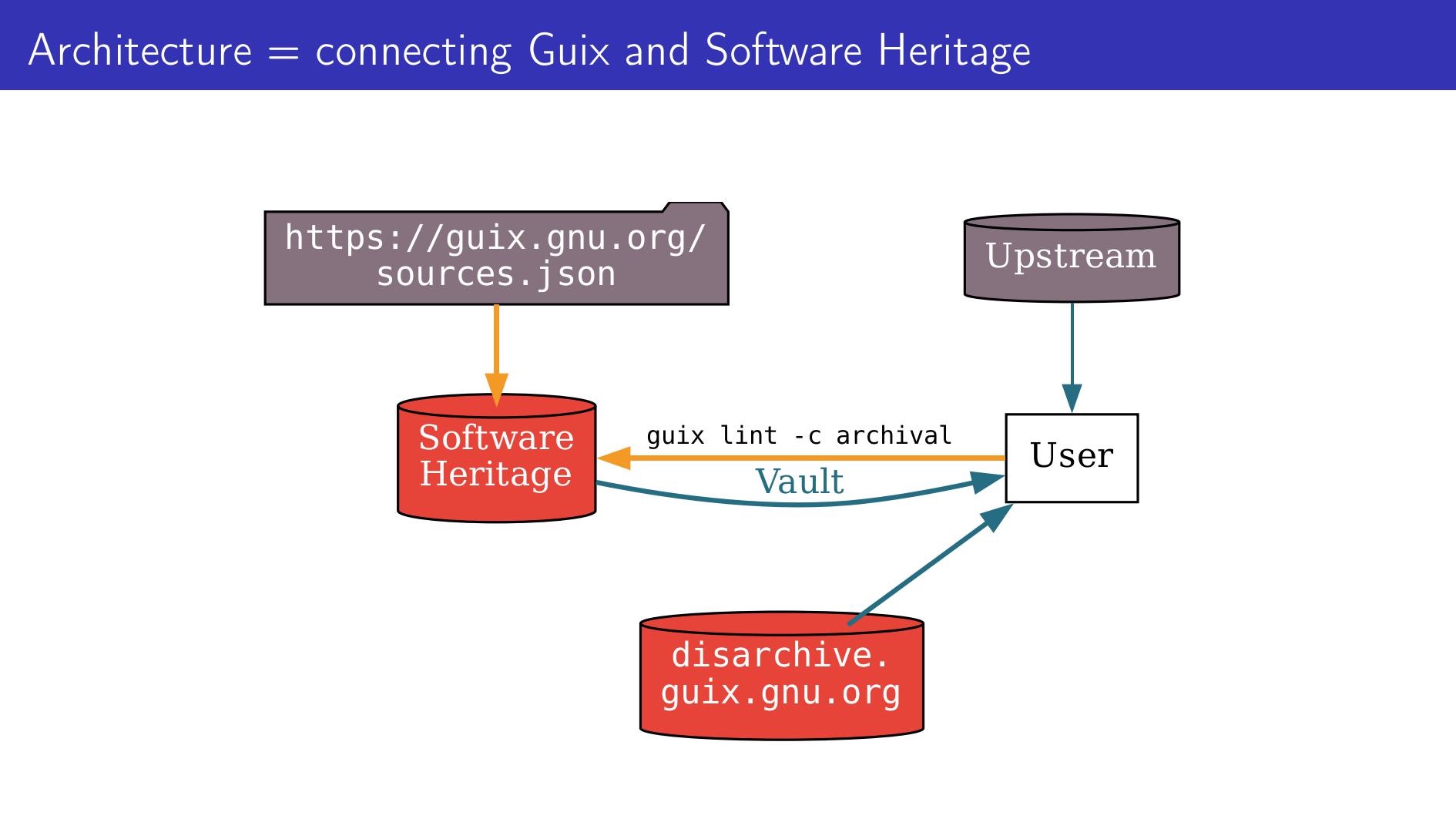
The architecture is twofold. On one hand, the Guix project feeds Software Heritage and the Disarchive database. The source code origin of all the packages for the last Guix revision is continuously listed and provided to Software Heritage, which ingests and archives it. At the same time, all the compressed tarballs are disassembled, and the metadata is saved. However, when Guix attempts to rebuild a computational environment with missing source code, the success of the rebuild hinges on how Guix originally packaged that code.
When the Guix package relies on the version-control-system (VCS) source code, Guix queries Software Heritage using the NAR identifier and gets back an SWHID. Then Guix asks the Software Heritage Vault to “cook” the files to fetch them. When a Guix package relies on a compressed tarball, Guix proceeds as follows: it queries the Disarchive database with the NAR identifier to obtain the SWHID, then requests the data from the Vault, and finally assembles a bit-identical compressed tarball using Disarchive metadata.
Credit: Simon Tournier
Connecting Guix with Software Heritage makes Guix the first free software distribution and tool backed by a stable source code archive.
What’s next
Work is still ongoing. On the Guix side, the machinery that exploits Software Heritage fallback needs amelioration. For instance, running a 2019 Guix revision now triggers the Software Heritage recovery mechanism as it was in 2019, in Guix’s early days. Although the recovery mechanism is continuously improving, it would be ideal if past revisions relied on current techniques for source code recovery. A further step towards improvement is ensuring complete source code coverage for all Guix revisions. However, this isn’t currently achieved, as Disarchive’s support for archive formats like lzip and zip needs additional development.
On the Software Heritage side, Guix provides various test-cases to challenge the “cooking” system of the Vault. Another direction is about the Disarchive database. The recovery architecture depends on the availability of this database, and today it’s only backed up by the Guix project. Incorporating this database into the larger Software Heritage framework would make the entire system more robust.
The integration of Guix and Software Heritage paves the way for more transparency and verification of the whole computational environment involved in scientific research. Scientific production should be robust to external service failures; for example, being able to audit or reuse scientific findings should not depend on the availability of platforms hosting source code. That’s why backing package managers with Software Heritage appears vitally important.