A new era of software engineering, cybersecurity, & AI

Software powers virtually everything we do, yet much of its history remains elusive. It’s more than just a tool; it’s a ‘concentrate of knowledge’—both human-readable and executable. Despite its critical role, current approaches to managing, preserving, and analyzing software in academia and industry are, frankly, far from satisfactory. Reproducibility suffers, documentation vanishes, and vital source code becomes impossible to find years later. That’s exactly why Software Heritage was born, says director Roberto Di Cosmo, speaking recently to students at the Oregon Programming Languages Summer School (OPLSS).
The big picture: A “telescope for software”
Imagine a project dedicated to going out, collecting, preserving, organizing, and sharing all publicly available software source code. That’s the core mission of Software Heritage. You can think of it as a reference catalog or a digital archive. But even more interestingly, it’s designed to be a real research infrastructure – like a “gigantic telescope that allows us… to do massive analysis of the galaxy of software development today.” Just as the James Webb Space Telescope explores the universe, Software Heritage aims to explore the universe of code. This monumental effort isn’t driven by venture capital but a long-term nonprofit multistakeholder initiative.
“In academia, software management is poor; in industry, it’s a looming disaster. A dedicated infrastructure is urgently needed to tackle these complex issues,” Roberto Di Cosmo
The scale is staggering: it holds almost 400 million projects, over 25 billion unique source code files, and more than five billion unique commits. Software Heritage tirelessly crawls more than 5,000 different code hosting and distribution platforms every single day.
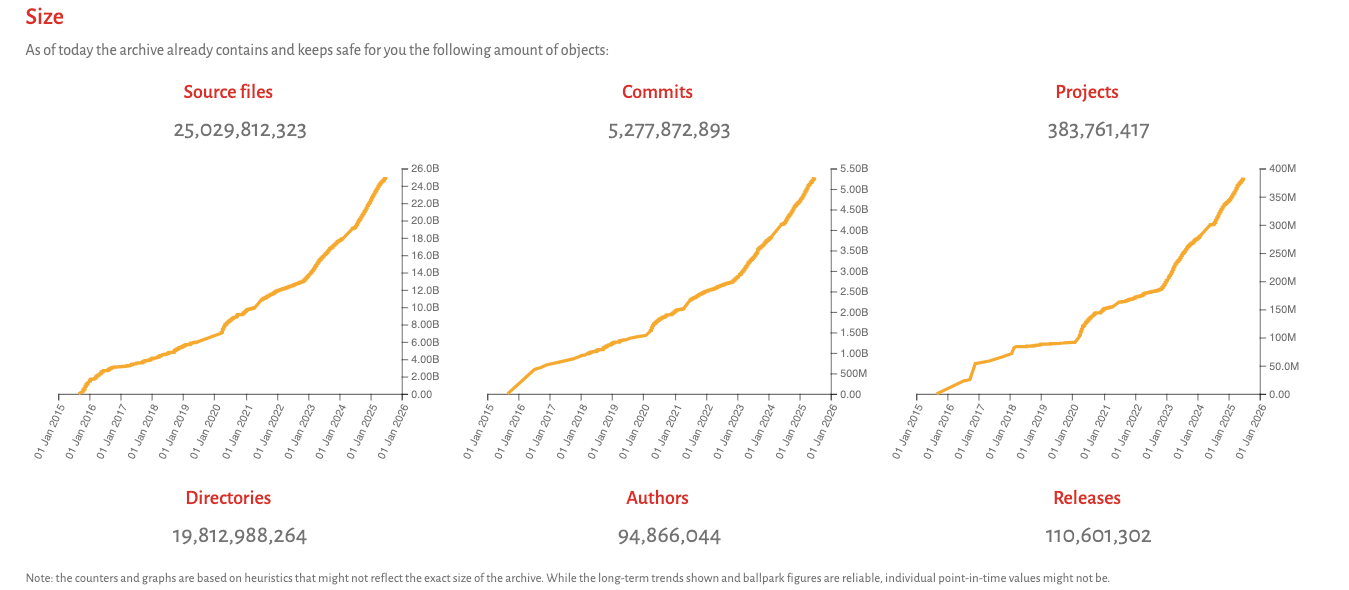
Building the beast: The unified cryptographic graph
So, how do you even begin to handle such an immense and diverse amount of data? The internet has standards like HTTP and URLs that make web crawling relatively straightforward. Well, in the world of software, every platform (GitHub, GitLab, npm, PyPI) has its own feed, API, and language for interfacing. On top of that, developers use many different tools to keep the version control of the system (Subversion, Git, Bazaar, Mercurial). To manage this vast, diverse data, Software Heritage developed adapters and a specialized tool for converting information from various version control systems. The goal is to consolidate all software development history into a single, large ‘cryptographic graph.’ This graph works like a blockchain, but without needing a distributed consensus algorithm.
It’s made up of six fundamental object types:
- Contents
- Directory
- Revision
- Release
- Snapshot
- Orgins
Each object is identified by a unique cryptographic permanent identifier called the Software Hash IDentifier (SWHID), a universal identifier officially the ISO/IEC international standard 18670. Origins are
identified by their URL. A significant feature of this structure is deduplication: if a file appears in 1,000 projects, it’s stored only once, preventing the storage of thousands of copies of the same content. This systematic collection and organization into a “single unified graph with a simple format” effectively performs a massive data cleaning and normalization sweep, which is often “the most annoying, time-consuming, not interesting part” of big data analysis.
“Nobody ever writes a piece of software from scratch today; we all re(use) directly or indirectly hundreds of components off the shelf,” Roberto Di Cosmo
Beyond traditional databases: Graph power
Traditional SQL databases are effective for tabular data but are “inherently limited when it comes to querying graph structures or performing ‘transitive closure,” Di Cosmo notes. SQL struggles with operations like tracing all the content within a directory’s full structure, or following a file back to its original source.
Software Heritage addresses this with a specialized framework called WebGraph, designed for compressing and traversing large graphs. This means the entire graph can fit into under half a terabyte of memory, supporting complex graph traversals that would be unfeasible with SQL.
Applications and insights from the graph
The power of this graph structure enables various analyses. Here are just a few examples:
- Tracing Android app origins: SQL can easily find specific files, like an Android manifest. But tracing that file’s entire history or its original source is like following a very intricate family tree. SQL isn’t designed to follow those deep connections, which is why the full graph is needed.
- Mapping global development activity: By analyzing email addresses linked to commits and their timestamps within the graph, researchers can map the geographical distribution of software development. This global view, which was previously impossible, revealed that over a third of public software originates in the US.
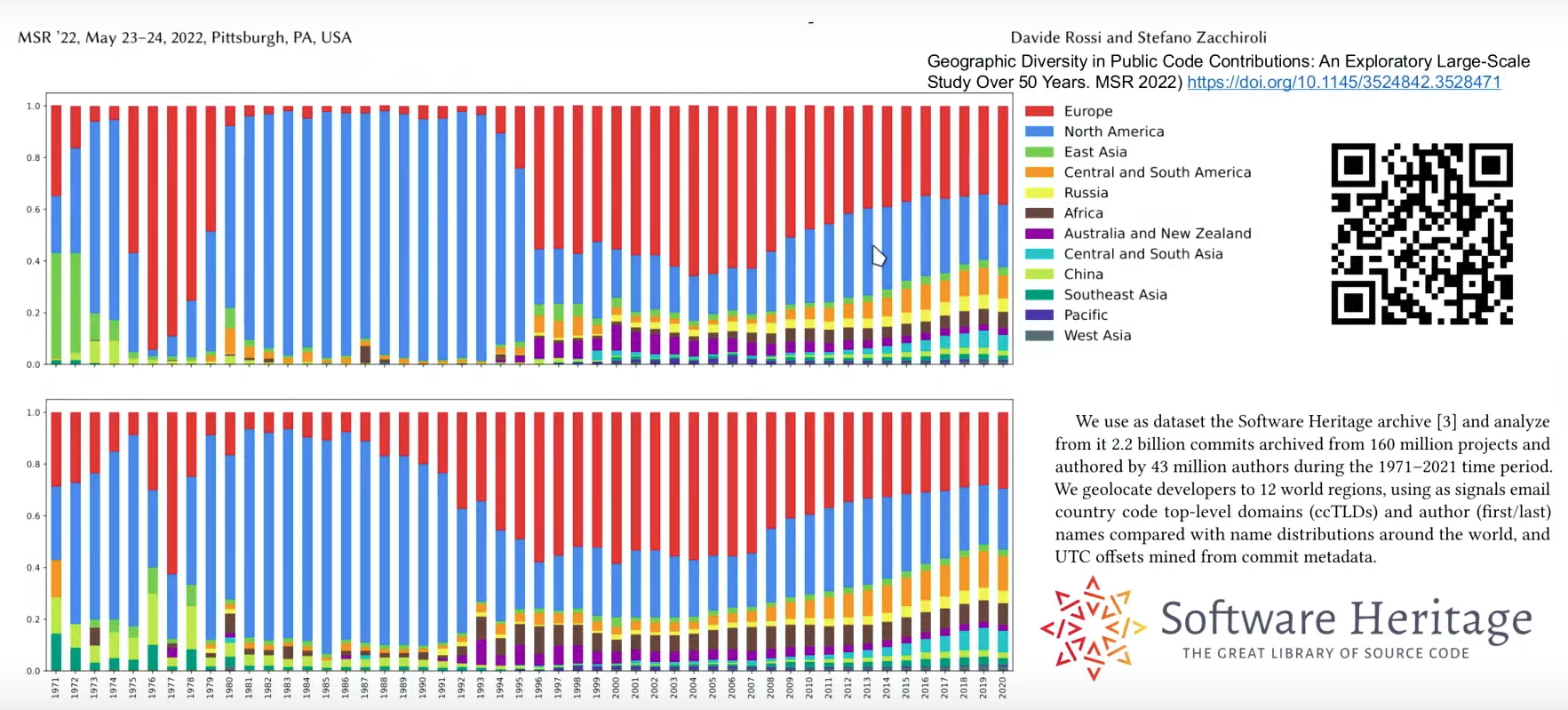
- Understanding programming language evolution: By identifying the approximate programming language of each file and using commit timestamps from the full graph, Software Heritage can illustrate the rise and fall of languages like Java and the explosive growth of source code modifications over time.
- Addressing cybersecurity (‘one-day vulnerabilities’): Traditional vulnerability tracking often focuses on individual projects. But the Software Heritage graph provides a global overview of all software, allowing researchers to trace connections across the entire codebase. This global perspective helps them identify, for instance, two million forks potentially vulnerable to ‘one-day vulnerabilities’ (known but unfixed issues)—a level of insight impossible without such a universally connected view.
- Measuring institutional impact: The graph helps analyze contributions from academic institutions. By linking email addresses in commits to specific universities and traversing the graph, researchers can measure these contributions. For instance, one university alone has contributed almost 30,000 individuals and 2 million commits to public software since 1970.
Future work with AI: Building trust through transparency
Software Heritage champions openness, traceability, and respect for code authorship among AI researchers and industry, training large language models (LLMs) on public source code. At the heart of this effort lies CodeCommons, a new initiative designed to create a shared, trustworthy, and open foundation for AI models built on code.
Three principles underpin this vision:
- Open foundational models: If a foundational model is trained on public code, it “must be given back,” at least through open or accessible licensing. AI should not privatize the commons that were built openly.
- Transparency: There must be full transparency regarding which code files from the archive are used in training. Thanks to the Software Heritage archive and its intrinsic identifiers (SWHIDs), each source file can be precisely referenced, ensuring traceable datasets.
- Opt-out mechanism: Code owners must retain agency. A robust opt-out mechanism should allow maintainers to request that their code be excluded from future model training.
This approach has already borne fruit in collaborative projects like The Stack v2, a public dataset of source code used for training code LLMs, built using GitHub repositories archived in Software Heritage as a core source of truth. Likewise, the StarCoder2 family of models demonstrates how high-performance generative models can be trained transparently on openly documented datasets.
CodeCommons continues this momentum, building the technical infrastructure, metadata, and ethical scaffolding needed to develop AI responsibly. It plans to integrate metadata from multiple sources (e.g., event feeds, research articles, CVEs, etc.), ensure deduplication at petabyte scale, and enable detailed attribution of training data. This is essential not only for compliance with emerging regulations like the European Union Artificial Intelligence Act (AI Act) and Cyber Resilience Act, but for maintaining trust between developers, researchers, and the public.
In short, the goal is clear: to enable powerful, open, and accountable AI models without compromising the integrity of our shared digital commons.
Learn more about CodeCommons: https://codecommons.org
Preserving our software commons: A shared responsibility
The mission of Software Heritage is no less than building a “modern Library of Alexandria for software” as a universal infrastructure that serves science, industry, culture, and society at large. This initiative, built with a long-term, nonprofit vision, is already delivering tangible results: enabling software citation, supporting reproducibility and traceability via ISO-standard SWHIDs, enabling AI training with transparency and openness through projects like CodeCommons, and uncovering millions of one-day vulnerabilities across forks to secure the open-source software supply chain.
But the scale of this mission calls for collective effort: if we care about the long-term integrity of science, the transparency of AI, and the resilience of our digital infrastructure, we need to invest in the foundations. Software Heritage is one such foundation – and it’s open to all.
Get involved
- Explore the archive: archive.softwareheritage.org
- Join the community: softwareheritage.org/community
- Use the graph: registry.opendata.aws/software-heritage
- Intrinsic identifier reference: swhid.org
Let’s build together the reference infrastructure that our software-powered world deserves.
Check out the lecture below or on YouTube