From lab to lecture hall: The rise of software in academia

How code powers modern academia
Software has become a fundamental tool across diverse academic disciplines. Data from the French Open Science Monitor shows that a significant proportion of publications across various fields mention the use of code or software. For example, in fundamental biology, 61% of publications mention using software. Similarly, in Earth, ecology, energy, and applied biology, the figure is 56%. Even in traditionally non-technical fields like computer and information sciences, 58% of publications mention software, while in engineering and chemistry, the proportion is 50%. This data underscores the critical role software plays in modern research, extending its influence beyond what might be considered traditional “tech” fields.
Charting the evolution of programming languages
Data collected by Software Heritage provides a fascinating look at the evolution of programming languages over the past 50 years. The number of software objects has grown exponentially, with contents showing an annual growth of 40.25%, and a doubling time of just over two years. This rapid growth is a testament to the increasing volume of code being produced. Looking at specific languages, older languages like C, C++, and Java dominated the early years of the survey, from 1990 to the early 2000s. However, languages like Python and JavaScript have risen dramatically in popularity in recent years. Python, in particular, has grown to become one of the most prominent languages in academic software, reflecting its widespread adoption for data science, machine learning, and general-purpose programming.
Where academic code lives and who writes it
A breakdown of contributions by institutional domain in France shows that Inria, the National Institute for Research in Digital Science and Technology, and Software Heritage’s parent organization, leads the way with 3,833 contributions, followed by Univ-lyon1.fr (2,806) and Univ-orleans.fr (1,555). The data also shows that from July 1992 to May 2025, there were over 46,533 software projects and more than 30,101 contributors
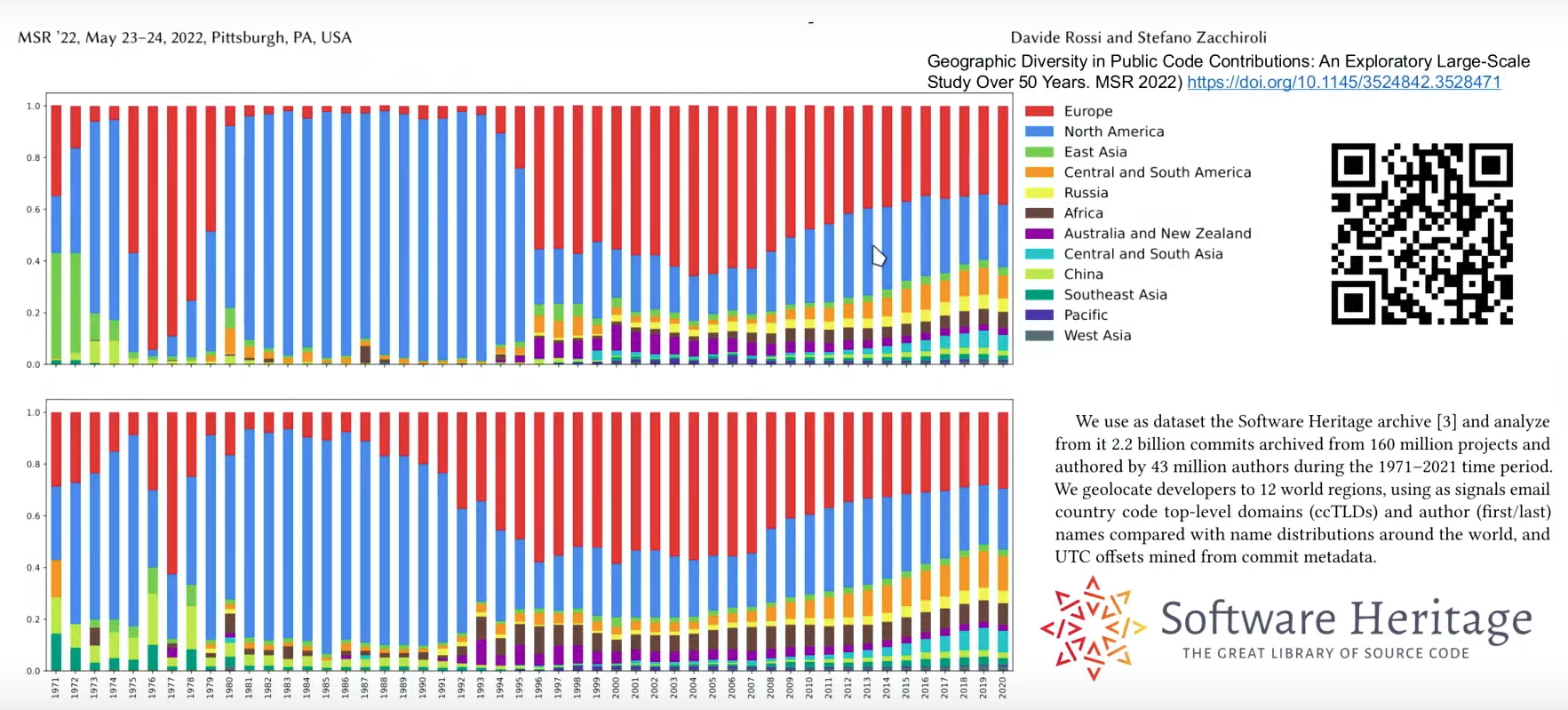
The distribution of code contributions worldwide reveals that Europe and North America have historically been the largest contributors of public code, followed by East Asia. However, the landscape of French academic software, as captured by the Software Heritage database, offers a more granular look at where code is being developed. Most of the code resides on platforms like GitHub.com, which accounts for the largest share of contributions. Other platforms, such as Gitlab.com and gitlab.inria.fr, also host significant amounts of academic code.
Licensing: A critical but overlooked aspect
One of the most surprising findings from the analysis is the licensing status of academic software. In France, an overwhelming 76.4% of projects lack any available license information. This creates a major problem for Open Science, as the lack of a clear license can make it difficult or impossible for other researchers to reuse, modify, or build upon the work. Only 18.9% of projects were found to have a license. Of those, the MIT license and GPL-2.0 were the most common, followed by Apache-2.0. This data highlights a crucial area for improvement within the open science community: the need to standardize and prioritize the inclusion of clear licensing information to ensure the long-term usability and integrity of academic software.
Keep up with other findings from Software Heritage with our publications section and stay up to date with our monthly newsletter.