Meet the SWHID: The end of broken links, broken builds

In the relentless rhythm of modern tech work, the deepest threat may not be a virus, but instability itself: projects compromised by dependencies that shatter and links that simply disappear overnight. URLs break, organizations merge, and domain names change, turning your software bill of materials (SBOM) and compliance documents into ticking time bombs. To beat dependency decay, developers need an identifier that’s universal, verifiable, and permanent, guaranteeing that any specific file or repository can be located, regardless of hosting environment or future domain control.
Enter the SoftWare Hash IDentifier (SWHID)
While the name might sound bureaucratic, the SWHID is cryptographically strong tech that ensures the integrity and persistence of software artifacts. It’s an intrinsic identifier you can compute yourself, guaranteeing that you are referencing an exact, unmodified piece of code. This technology was the focus of an Enabling Linux In Safety Applications (ELISA) project seminar, where Thomas Aynaud, CTO for Software Heritage, laid out why you “will not be able to live without it.”
Decentralized trust: hashing the reality of code
What makes SWHID so powerful? It’s intrinsically linked to the content it identifies. This is not some external, version-based label assigned by a developer or an organization; this is a cryptographic signature. It begins with the simple prefix swh and includes a schema version (currently version one), followed by the object type. The object type specifies the granularity: content (a file), directory (something containing other directories or content), revision (a modification done by someone), release (which targets a specific revision), or snapshot. You can also add context to the identifier, such as origin context, to describe a specific object in the context of a particular repository, like the Apollo source code.
“It’s decentralized—there is no central authority, no one is selling you an SWHID. You can already compute an SWHID from your own code if you want, and it’s applicable to your code, even private, because it’s decentralized and intrinsic,” Thomas Aynaud, CTO, Software Heritage
The computation process is decentralized and robust. If you have the object—say, a content file—you compute its SWHID using a SHA-1 hash of that content. This decentralized and intrinsic nature means you can compute the SWHID on your own laptop or for private code, without relying on any central authority. This approach extends upward: the SWHID of a directory is a SHA-1 hash of the SWHIDs of all the contents and subdirectories within it. A revision’s SWHID is computed from the hash of the main directory, the previous revision, and associated revision data. This strong connectivity means that if you modify the file, the directory SWHID will change, or if you change a revision before the current one, the SWHID of your new revision will change, providing a strong integrity guarantee.
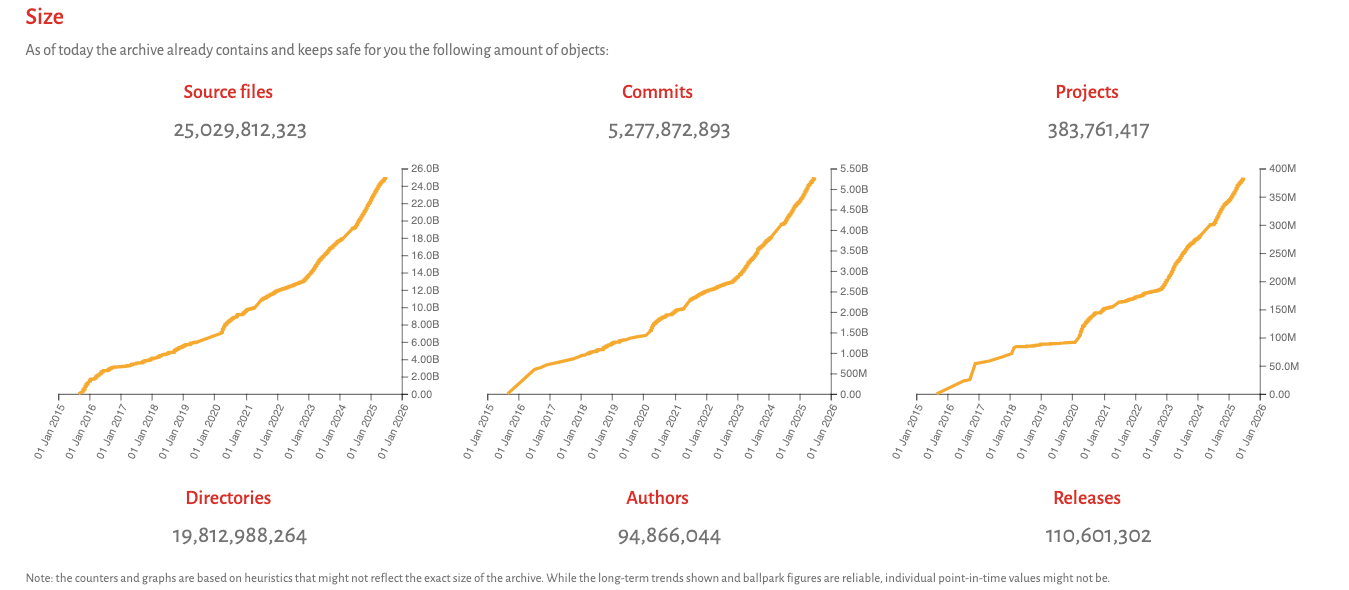
This system was initially conceived by Software Heritage, a nonprofit organization focused on building the “Library of Alexandria of software source code.” Its mission is to harvest, preserve, and open-source all public code. Our organization believes the source layer holds vast human knowledge too critical to lose. Today, the Archive holds 26 billion duplicated source files, alongside 5 billion code revisions, providing a global development history permanently archived in a uniform data model. This data structure is built on a Merkle directed acyclic graph (Merkle DAG). This functions like a specialized, non-monetary blockchain focused on data integrity and version control.
A standard is born: SWHID breaks free
Here’s the main takeaway for the industry: SWHID is becoming independent from Software Heritage. This is no longer just a project backed by a single nonprofit. The SWHID has evolved from an internal identifier, once tightly coupled with the organization’s data model, to achieve ISO standard status in April 2025.
This standardization means that SWHID is cross-platform and tooling independent, applicable across Git, Mercurial, big monorepos, or multiple repositories, regardless of your hosting or internal naming conventions. It’s not dependent on what you use for hosting or how you name your repository. An open, transparent, collaborative, and vendor-neutral governance structure has been established. The idea is to make decision-making based on consensus and ensure an open process to produce an improved specification. The project now has a dedicated GitHub-style organization and a core team divided into maintainers (who schedule and lead meetings) and editors (who ensure coherence and adherence to guidelines) to keep the standard viable and widely adopted.
In practice
The power of the Software Heritage scanner lies in its ability to flag anything unexpected immediately. Aynaud demonstrated this by running the scanner on his small personal repository. While the majority of the repository—including files for licenses, citations, and development containers—was composed of known open-source code, the scanner provided a critical finding: 96% of the files were known, but it immediately flagged one unexpected file that had been altered with malicious code.
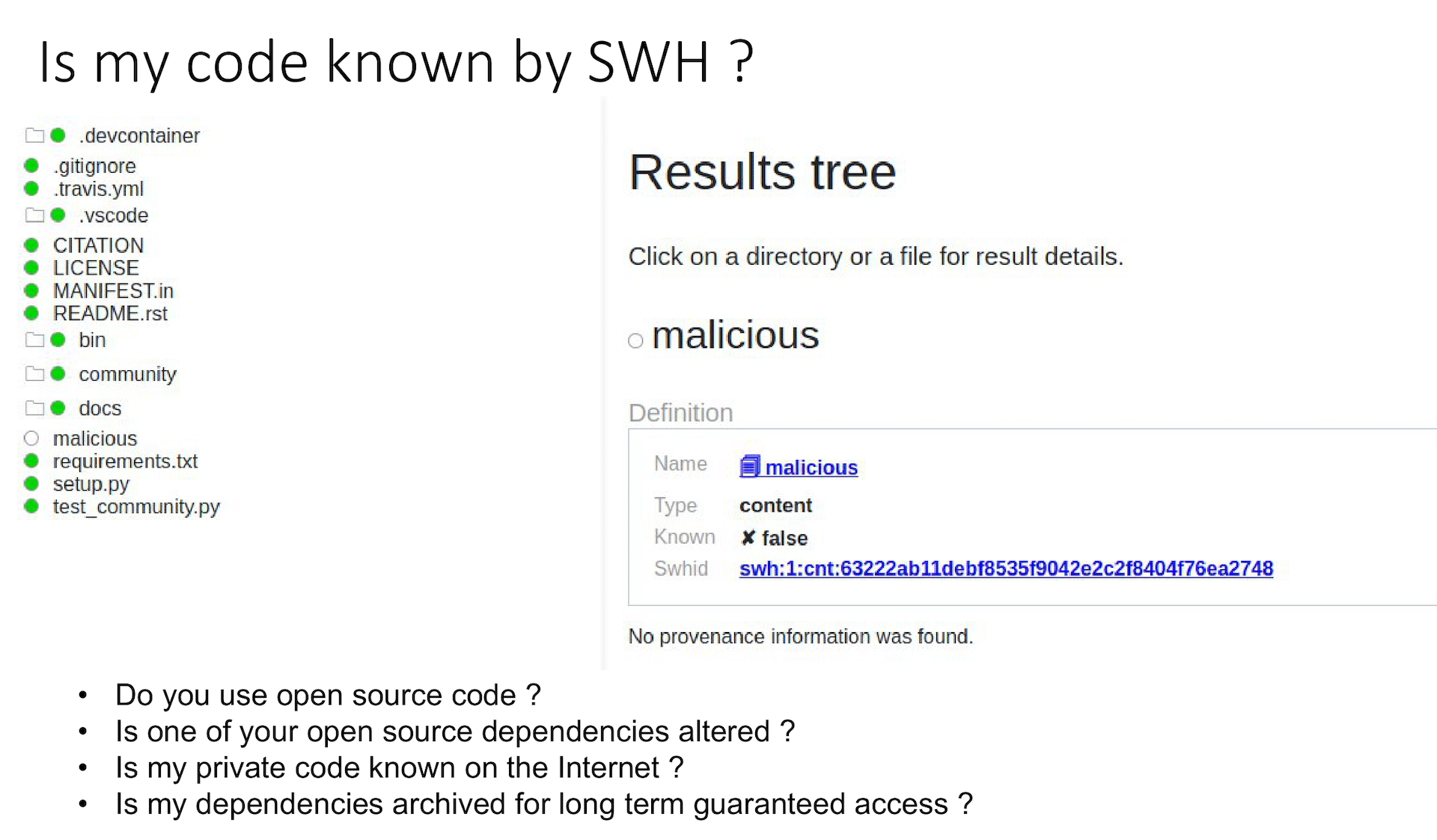
When examining the result tree, the source files that he had recently added—the malicious file—were not known by Software Heritage.
While the intrinsic nature of the SWHID means you can compute an identifier for any file, even a malicious one, the fact that the archive reported that this SWHID was “not known and no provenance information was found” provides a crucial signal. This capability allows developers to answer a critical security question: Is any of my private code currently present in the public repositories on the internet? Am I using open-source code in a private repository? Has an open-source dependency I copied into my project been subtly altered?
Where’s my code
The ultimate proof of the SWHID’s persistence is its ability to retrieve vanished code. Aynaud demonstrated this by constructing a specific Software Heritage URL using a known SWHID identifier (starting with swh:1:cnt:). He successfully used this SWHID-based address to “get the code back from software.” Critically, this wasn’t just any arbitrary file; but something that happened to him. The project was migrated to GitHub, its original repository and vital history became virtually unfindable after the host platform, Bitbucket, dropped support for Mercurial. The SWHID acts as your immutable, long-term retrieval key. If the original code disappears or its hosting platform fails, Software Heritage guarantees you can still get it back.
Making SBOMs easy
It’s also practical for improving Software Bill of Materials (SBOMs), including formats like CycloneDX and SPDX. In the declaration section of an SBOM, the SWHID can replace unstable metadata such as package names and version numbers. This intrinsic identifier means you are “really declaring that you rely on this specific code,” Aynaud notes, making the reference stable and tamper-evident for compliance. The IDs can be used to reference the exact start and stop points of an issue within a project’s history, replacing vague package references. And if developers are already computing MD5 checksums of files, they’re only one step away from computing the SWHID.

The potential applications for SWHIDs span across the industry. For instance, if you distribute software using the GPL license, distributing software requires providing the Corresponding Source. Relying on a tarball URL in a user manual creates a risk, as that link can break due to company reorganization or domain changes, leading to non-compliance. A better approach is to deposit your code with Software Heritage, retrieve the SWHID, and include that immutable ID in your user manual, guaranteeing long-term findability.
Similarly, for artificial intelligence compliance, SWHIDs simplify documentation by allowing easy verification and referencing of the exact source files used to build the training datasets.
What’s next: Open licensing
Current SWHID computation tools often use the GPL, which complicates integration. Future development is focused on releasing new tools under permissive licenses (like MIT or BSD) to simplify adoption. This shift also fulfills the requirement for an open implementation as part of the ISO standardization process. Plans are also in the works to improve provenance detection to ensure that when a SWHID is found in the archive, users can reliably get the “most important or maybe the oldest” origin of that piece of code.
Common questions about the SWHID
The 47-minute seminar ended with a Q&A. If you have more questions, check out the SWHID FAQ.
Q: Does Software Heritage select and store only the source code, or is documentation (like user manuals and release notes) included as well?
A: We archive everything we can find within a repository; our strategy is not to select what is archived. This includes documentation, markdown files, and even small binary files. The only constraint is that we do not archive individual files larger than 100 megabytes. While we focus on source code, if documentation is in the repository, it gets stored, provided it meets the file size limit.
Q: Does the SWHID take into account only the file’s content, or does it also look at metadata? Also, are the configuration parameters used to create the SWHID encoded in the ID for recreatable results?
A: The SWHID for a single file is based only on the content of the file itself—it is simply a hash of the file. No external metadata is included in the SWHID calculation for a given file.
The parameters or “configs” mentioned are not about the mathematical hash computation for a single file. They relate to computing the SWHID for an entire repository. These parameters determine which files to include in the overall repository SWHID (e.g., excluding the hidden .git folder, handling Git submodules, or managing large files). This ensures that the final repository ID is consistent and only reflects the relevant source code.
Q. How can I compute a SWHID on software that isn’t already in the Software Heritage Archive?
A. The primary tool is the Software Heritage Python package. Other academic implementations are available on SWHID.org.
Get involved
Getting started with SWHIDs is straightforward: compute them locally for your code, update your SBOMs, and integrate them directly into your development tools.
The SWHID provides the precise, persistent reference frame the software world has always needed, whether you are a security engineer demanding integrity guarantees or a compliance officer requiring immutable proof.
We need the community’s expertise to advance this standard. You can contribute by joining the SWHID governance process, developing essential tooling, or continuing to archive software at Software Heritage. Find the specification and join the discussion at SWHID.org—your technical input is highly valued.