CodemetaR Author streamlines software metadata updates

By Frédéric Santos, Software Heritage Ambassador
Think of software metadata as the essential ID card for any software package. It’s that structured information that tells you all about the program: its name, version, who made it, what license it uses, what other software it needs to run, and other important details. For R packages specifically, this means information about what the package actually does, which other R packages it depends on, the minimum R version it requires, and even its intended purpose.
To cut through the tangle of diverse, language-specific metadata formats, the Codemeta project stepped in. Its mission is to standardize and improve the sharing of software metadata, offering a universal schema (built on a JSON-like syntax) to describe software. This common approach helps turn metadata into a format that can easily “cross-work” between many different programming languages, making software easier to discover, cite, and reproduce.
This post offers an overview of the 14-minute video tutorial, highlighting how the codemetar R package simplifies generating and updating this crucial Codemeta metadata for your R packages.
Why bother with organized software metadata?
Keeping your software metadata organized and fresh isn’t just a nice-to-have; it’s critical for several reasons. If you’re a researcher, for instance, you know how vital it is for your analyses to be reproducible by others. Accurate software metadata is key here, since it specifies the exact software versions and dependencies that people need to replicate your work precisely. It also tells authors how to properly cite the software they’ve used in their articles, which is very important. But beyond just reproducibility and citation, well-structured metadata acts like a beacon for discoverability. Search engines can find your software more easily, linking it to relevant keywords. Even popular software repositories like GitHub would be a nightmare to navigate without good metadata. So, truly, any software developer – and R developers are definitely included – should pay close attention to how they specify metadata in their packages.
The R-specific way and its bottleneck
When you build an R package, the standard, built-in way to define all this necessary metadata is through the DESCRIPTION file. This file is where you’ll find essential fields like Title, Description, Author, License, and Imports. These details are crucial for users to grasp the package’s purpose and requirements, and they help external tools or repositories reference your package better. You can even generate a DESCRIPTION file template using R’s built-in functions or the devtools package. Sometimes, you might also find richer, though less structured, info in a README file.
But here’s the catch: the DESCRIPTION file has a very specific R-centric format or syntax. This becomes a real headache because other programming languages have their own unique ways of handling package metadata. Take a Julia package, for example; it might use a Project.toml file. Or an Emacs Lisp package, where metadata lives right in the header of its main file. The syntax and structure of these files are vastly different from R’s DESCRIPTION file. This language-specific approach creates a big problem for automatically collecting software metadata across different ecosystems, as each language demands a specific process for data extraction. This challenge directly impacts search engines, software archives, and repositories that aim to gather and organize information about a wide variety of software projects.
Enter Codemeta: The Universal Translator for Software Metadata
To tackle this tangled mess of different metadata formats, the Codemeta project stepped in. Its main goal? To offer a single, universal format for describing software that isn’t tied to any specific programming language. Codemeta achieves this by using a common schema based on a JSON-like syntax. By creating a codemeta.json file, developers can transform their software metadata into a format that can easily “cross-work” across many different programming languages. This standardized approach is a game-changer for improving software discoverability, reproducibility, and citation.
You’d typically place a codemeta.json file at the very root of your R package directory, right alongside your DESCRIPTION file. Since it’s not part of the standard R package build process and doesn’t inherently belong to the R universe, you can just add it to your .Rbuildignore list. This ensures it gets skipped when your package is built, preventing any issues. While the JSON format used by codemeta.json files is powerful, it can be quite heavy, challenging for humans to read, and even harder to type manually.
The hassle of manual codemeta.json management
Given how complex JSON can be, trying to manually create or update codemeta.json files is, frankly, impractical. Sure, there are some automatic generation options, like websites provided by the Codemeta project team, where you fill in fields to get your JSON file. There’s even a newer version (a fork) of the Codemeta generator that can auto-fill fields if you just give it a GitHub or GitLab URL. These are nice, but still require you to manually update the codemeta.json file every time you release a new version of your R package. This opens the door to forgetting to update the file, leaving you with outdated codemeta.json information. Clearly, there’s a need for a more integrated, automated solution, especially for developers who frequently update their packages.
Enter codemetar: Your R Package metadata sidekick
This is precisely where the codemetar package steps in. The codemetar package is designed to help R developers effortlessly generate, parse, modify, and update codemeta.json files for their R packages. It’s readily available on CRAN, so you can install it with the usual install.packages(“codemeta”) command.
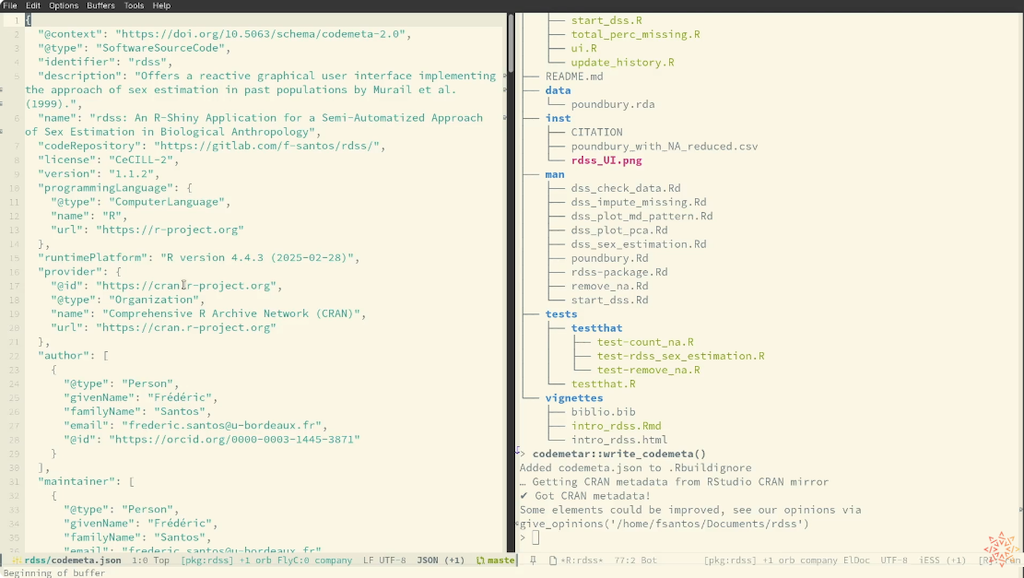
The real magic of codemetar lies in its ability to automatically pull relevant information from your R package’s DESCRIPTION file and seamlessly convert it into the Codemeta JSON format. A simple function call like write_codemeta() is all it takes to extract all that useful metadata from your DESCRIPTION file and pop it into a new codemeta.json file. What’s more, codemetar can even dig into your README file to extract extra metadata, like badges showing continuous integration services or minimum R version requirements. And here’s a neat little trick: codemetar automatically adds the generated codemeta.json file to your .Rbuildignore file, ensuring it never messes with your R package build process.
Painless updates and CRAN Integration
A big benefit of using codemetar is how it simplifies keeping your package’s metadata fresh throughout its entire development lifecycle. This is important when you’re pushing out new versions, bringing in new contributors, or even changing where your development is hosted (like moving from GitHub to GitLab). And for those of you already using devtools::release() to push your packages to CRAN, get ready for some truly seamless integration. When this function runs to submit a new package version, it automatically checks if your codemeta.json file is up-to-date and matches the metadata in your DESCRIPTION file. If there’s a mismatch, devtools::release() will give you a warning. This effectively acts as a safety net, ensuring you’ll never forget to update your codemeta.json file when you’re submitting to CRAN.
In a nutshell, the codemetar R package streamlines how R developers manage their package metadata. By offering an easy, automated way to create and maintain codemeta.json files, codemetar not only boosts the discoverability and citation of R packages but also helps ensure their reproducibility by standardizing metadata in a universally understood format.
About Frédéric Santos
Frédéric Santos is a data analyst at CNRS, the French National Centre for Scientific Research. His programming expertise spans R, Julia, Bash, and Emacs Lisp. As an ambassador, his fields of expertise include machine learning, notebooks, and reproducible research. You can explore his projects on GitLab and GitHub as well as his website. He’s been a Software Heritage Ambassador since 2023.