
There are so many ways in which digital information can be lost, altered, or rendered useless.
- Accidental or malicious human intervention can lead to deletion of important information, and missing, imperfect or untested backup procedures may prevent its recovery.
- Change in logical formats, or loss of the needed execution environment can lead to the inability to access, read, interpret, validate or use digital information.
- Missing, or inadequate reference mechanisms can destroy our ability to identify the information that is relevant, even when it is not lost, and is still readable otherwise.
- Encryption protects our privacy, but also prevents recovery of information in case the keys are lost.

A few examples are worth 1000 words

Missing source code, on a massive scale
We will never know how effective has been the gigantic effort to fix the well known Year 2000 bug (or Y2K) before december 31st, 1999: the great disasters that were announced never actually materialised, but is it because the important instances of the bug were fixed in time, or just because no important bugs were really present in the first place?
No matter what really happened, the race for fixing the Y2K bug unveiled that in 40% of the cases, the affected parties (industries, institutions, etc.) had lost or misplaced the source code of the software that needed fixing. In some cases, they never had the source code in their possession!

Malicious attack of software infrastructure
In the Summer of 2014, an attacker gained access to the CodeSpaces’s control panel and demanded money in exchange for releasing control back to Code Spaces (see CodeSpaces website as of August 2014).
When Code Spaces didn’t comply and tried to take back control over its own services, the attacker began deleting resources.
CodeSpaces was a company offering hosting solutions for Software development, and this attack endangered seriously all software hosted there.
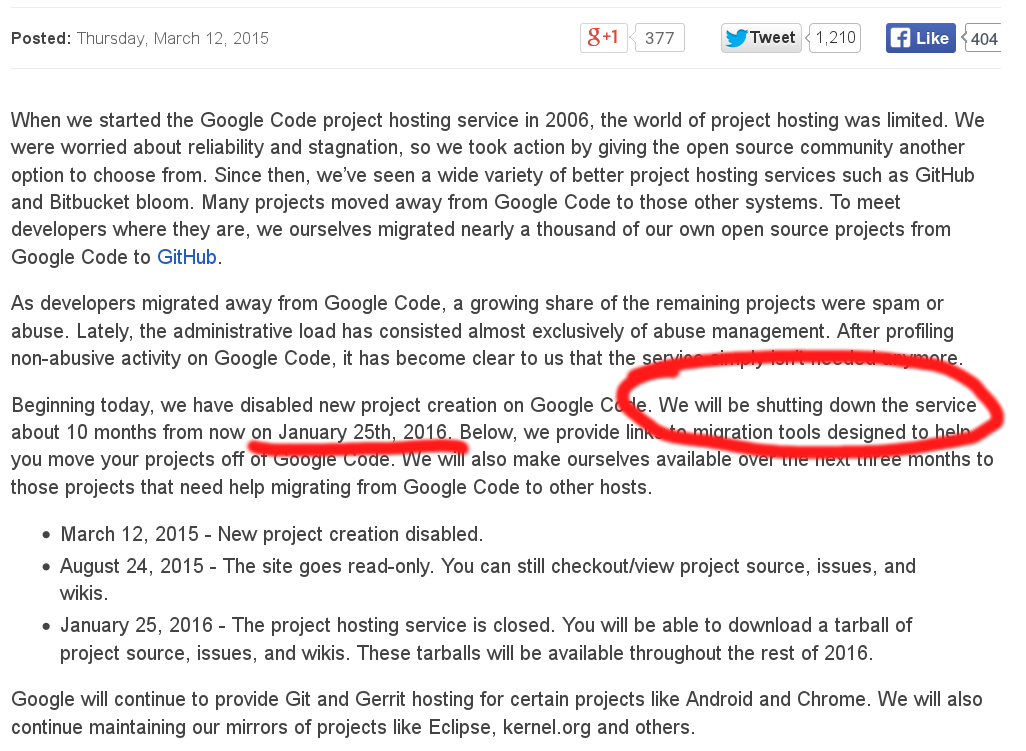
Shutdown of software development services
In March 2015, Google announced the demise of the widely used, and greatly appreciated Google code service, that was used for years since its launch in 2006.
While a migration calendar has been announced, by the end of 2016 all the code hosted there will be gone, with just a few exceptions.
What about the important pieces of software whose maintainers have gone offline? Who will take care of this knowledge at risk of being lost?
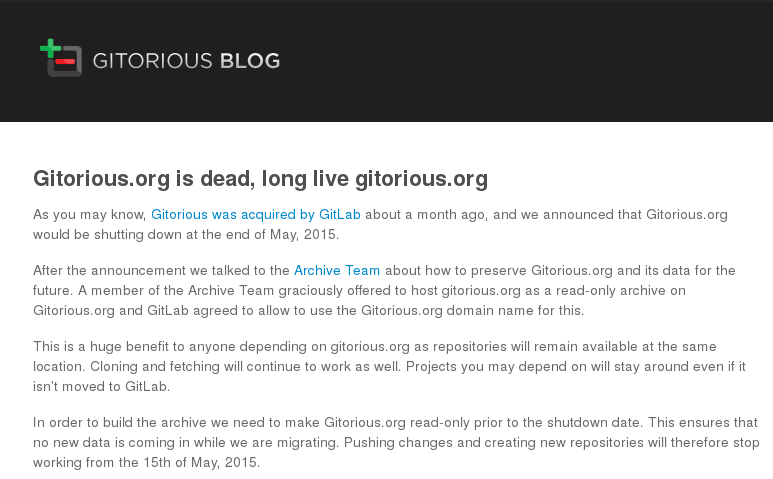
Shutdown of software development services (again)
In May 2015, Gitorious also announced that its free software development hosting services would be discontinued. Thanks to the effort of the Archive Team, a read-only copy of the software projects originally developed on Gitorious will be maintained. But for how long?
And what will we do when the next merger, acquisition or change in business priority of some major software development actor comes by?

Inadequate reference mechanisms
It is well known that URL (Uniform resource locators) do not provide persistence.
… there is no general guarantee that a URL which at one time points to a given object continues to do so
T. Berners-Lee et al. RFC 1738
And yet, that is still today the mechanism most commonly used for referencing information that should be accessible in the long term, like scientific articles, with disastrous consequences when it comes to finding the software that is important for a particular experiment or application.
… the half-life of a referenced URL is approximately 4 years from its publication date
D. Spinellis. The Decay and Failures of URL References.
Communications of the ACM, 46(1):71-77, January 2003.
The Software Heritage project
We are building the largest archive of software source code ever conceived. We are trying to ensure we will not lose important software or its development history anymore. We are trying to maximize our chances of not losing parts of our software commons.