How to preserve legacy code with Software Heritage
The Software Heritage Acquisition Process, or SWHAP, is a method developed by the Software Heritage team and its partners for saving and archiving older source code. This post and the companion 10-minute YouTube video offer an overview of what SWHAP is all about.
Understanding Software Heritage
First, a quick refresher on Software Heritage. It’s a non-profit dedicated to building a universal, open archive of source code. Usually, Software Heritage works by automatically collecting and saving public code already hosted on forges – online platforms like GitHub or GitLab where devs keep their projects. This automated system is massive, having already archived 400 million projects and over 25 billion unique source code files to date.
The challenge with legacy code
But what if your code isn’t sitting on one of these public platforms? That’s the core issue with “legacy” source code. This is code that isn’t easily accessible online – maybe it’s printed on paper, stuck on an old floppy disk, or just living on your hard drive. Getting this kind of code properly archived for the future is where things get complicated.
Why preserving source code matters
You might wonder why we bother preserving old, seemingly outdated code. Beyond its immediate function, source code is an invaluable record of technological history and human ingenuity. It safeguards intellectual heritage, allowing future generations to learn from past solutions and understand the evolution of software that underpins our world. Preserving these digital artifacts provides crucial context for researchers, historians, and developers to trace ideas and comprehend the thought processes behind their creation.
Margaret Hamilton standing beside the Apollo Guidance Computer (AGC) source code, now archived at Software Heritage.
This perspective highlights code’s role as a human document, not just machine instructions. If you have valuable source code you want to preserve but aren’t sure how, the SWHAP process is designed to help.
How to SWHAP: The basics
The SWHAP process involves two primary steps:
Get your legacy source code onto a forge. In most cases, GitHub is the preferred platform, simply because it’s so widely used.
Once it’s on GitHub, we can then trigger Software Heritage’s automated system. This ensures your code is securely pulled into the Software Heritage Archive.
What you’ll need
SWHAP requires a few specific tools and some prep work. First, if your code isn’t already in a digital format – say, if it’s a printout – you’ll need to transcribe it into an electronic file. After that, you’ll need:
A GitHub account
A Linux command-line interface
Git installed on your computer
A secure SSH key configured for your GitHub account.
If these technical requirements seem daunting, our detailed SWHAP guide provides comprehensive setup assistance. You can also join our mailing list to share information with other rescue and curation teams.
The pitfalls of GitHub uploads
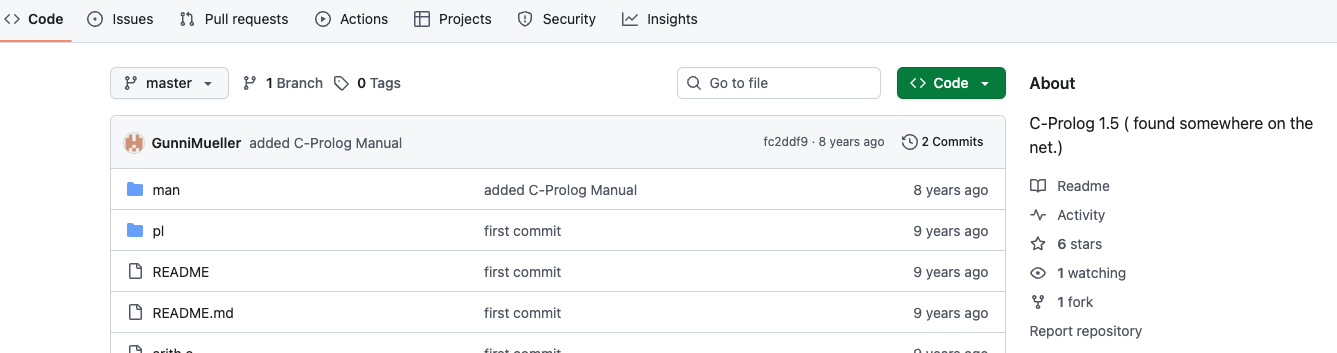
You might be tempted to skip these steps and just manually upload your code directly to GitHub. But that approach can cause significant problems. Here’s a real example of what SWHAP aims to prevent: a public GitHub repository for C-Prolog. While this is historically important code—an early interpreter from 1982—a glance at the screen reveals a GitHub user uploaded it in 2017.
A casual visitor might assume the code is much newer than it is, and that the GitHub user, not the actual creator, wrote it. Worse, if you try to verify the code’s accuracy or origin, the only information is that it was “found somewhere on the net.” That offers no way to confirm its true source or authenticity. This is why SWHAP matters: it makes sure your code lands on GitHub with the correct history and vital information, preventing misunderstandings for anyone looking at it in the future.
Setting up your GitHub repository for SWHAP
Before diving into the precise steps, let’s go over what your GitHub repository should look like for SWHAP.
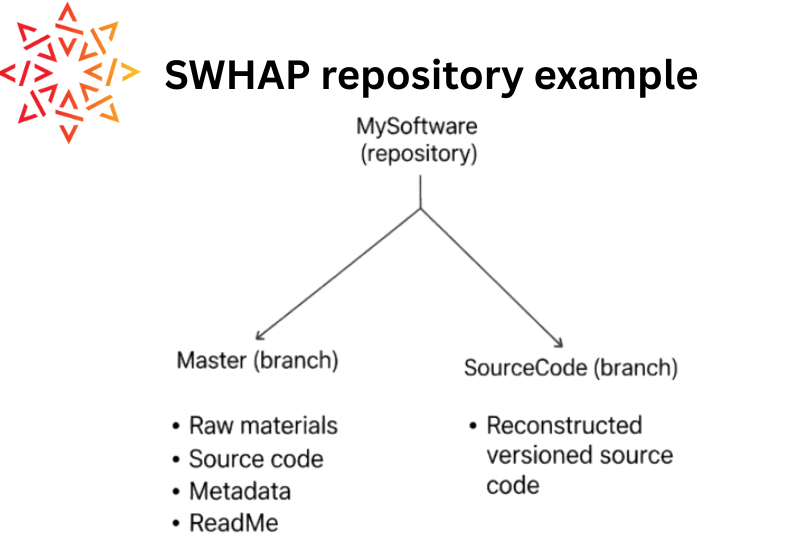
In this example, the code is called “MySoftware,” and the repository bears that name. It has two main sections, or branches:
The master branch: This holds all the initial information for preservation, including metadata and the code’s origin. Typically, there are three key folders:
raw materials: For any original documents related to the code you’re preserving (e.g., a scanned paper listing).
source code: This is where the machine-readable version of your code goes.
metadata: As the name suggests, this folder holds all the descriptive information about your software.
The source code branch: This becomes crucial if your software has multiple versions. For instance, if you have 10 different iterations, a future user might not want to sift through each one. However, seeing the code’s development over time is still very valuable. In this branch, we’ll recreate the software’s development timeline, adding each version sequentially using Git’s commit feature. This provides a practical way for anyone viewing the repository in the future to track how the source code evolved.
That’s it for the overview. Check out part two, which has a more detailed, step-by-step explanation of the SWHAP process.